
Nano vLLM: A Tiny Inference Engine that Teaches you the Big Ideas Behind Optimized LLM Deployment
A deeper look into vLLM in less than 1k lines

👋 Hi everyone, Hamza here. Welcome to Edition #29 of a newsletter that 15,000+ people around the world actually look forward to reading.
We’re living through a strange moment: the internet is drowning in polished AI noise that says nothing. This isn’t that. You’ll find raw, honest, human insight here — the kind that challenges how you think, not just what you know. Thanks for being part of a community that still values depth over volume.
🎓 Want to up skill as AI Engineer?
Join the next cohort of my Agent Engineering Bootcamp (Developers Edition) April 8
Watch the free 4-session Agent Bootcamp playlist on YouTube
If you’ve ever felt like LLM deployment is a black box that everyone else somehow understands except you — this one’s for you. Let’s open it up together.
You’ve done the hard part. You fine-tuned a model, it runs beautifully in your notebook, loss curves look great, outputs are solid. Then you try to serve it to real users — and suddenly you’re drowning in questions you can’t answer. Why is latency spiking under load? Why is VRAM usage ballooning? What is batching actually doing to your throughput? If this sounds familiar, you’re in good company.
Here’s the frustrating reality: most developers treat LLMs as black boxes — and that works fine until it doesn’t. Full vLLM is an incredibly powerful inference engine, but its 100,000+ lines of code aren’t designed for learning. They’re designed for performance at scale. Trying to understand LLM inference optimization by reading vLLM’s source is like trying to learn how a car engine works by dissecting a Formula 1 race car — technically accurate, practically overwhelming.
That’s where this nano vLLM tutorial comes in. nano-vLLM is a ~1,000-line Python reimplementation of vLLM’s core ideas — KV caching, PagedAttention, continuous batching — written to be read, not just run. In this article, you’ll get a guided tour of what nano-vLLM is, why each of its core mechanisms exists, how to trace those mechanisms in the code, and how that understanding transfers directly to production-grade open source LLM deployment.
🔑 Key Takeaways
📦 nano-vLLM is a learning tool, not a production system — its minimal codebase (~1,000 lines) deliberately strips away complexity so you can trace exactly how a real inference engine works, making it the fastest path to understanding what full vLLM is doing under the hood.
⚡ KV caching is the single biggest lever for LLM inference speed — it stores and reuses key-value pairs from the attention mechanism instead of recomputing them on every token.
🧩 PagedAttention solves the memory fragmentation problem — borrowing from OS virtual memory, it allocates attention memory in discrete blocks to dramatically improve GPU utilization.
🔄 Continuous batching keeps GPUs busy by treating every token step as a scheduling opportunity — slashing idle time compared to static batching.
🧠 Studying a minimal reimplementation accelerates your intuition — the mental models transfer directly to vLLM, TGI, and TensorRT-LLM in production.
What Is nano-vLLM and Why Should You Care?
Before we get into the mechanics, let’s establish exactly what nano-vLLM is — and just as importantly, what it isn’t. Getting this framing right separates developers who use it as a powerful learning accelerator from those who dismiss it as a toy.
 versus full vLLM codebase (100k+ lines) with key components labeled")
The Problem With Learning From Production Codebases
Production LLM inference engines like vLLM, Text Generation Inference (TGI), and TensorRT-LLM are extraordinary pieces of engineering. They handle distributed tensor parallelism, custom CUDA kernels, fault-tolerant API layers, and dozens of edge cases that only surface at scale. But that same depth makes them nearly impenetrable when you’re trying to understand the core ideas rather than just use the tool.
Open vLLM’s codebase hoping to understand how KV caching works and you won’t find a clean function — you’ll find the concept scattered across abstraction layers, tangled up with GPU memory management code, scheduling logic, and async runtime machinery. It’s not that the code is bad; production code optimizes for reliability and performance, not for teaching. The Formula 1 analogy holds: it’s the pinnacle of mechanical engineering, but you wouldn’t hand one to a student learning how internal combustion works.
The result is that most ML engineers learn theory from papers and blog posts, then use vLLM as a black box — never really bridging the two. That gap costs you every time you need to debug a throughput problem, tune a deployment, or evaluate whether a new inference optimization actually matters for your workload.
Enter nano-vLLM — A Minimal Reimplementation Built for Clarity
nano-vLLM was built to close that gap. It’s a deliberately minimal Python reimplementation of vLLM’s core scheduling and memory management concepts — written so you can sit down and trace the full execution path from request intake to token output in a single afternoon. The entire codebase is roughly 1,000 lines, not because it cuts corners on the ideas, but because it strips away everything that isn’t the idea.
The project lives on GitHub (Source: https://github.com/GeeeekExplorer/nano-vllm) and explicitly frames itself as educational. Every major concept — KV cache allocation, block tables, the scheduling loop — is implemented in clean, readable Python without the performance scaffolding that would obscure it in production code. The ~1,000-line footprint isn’t a limitation; it’s the entire point.
nano-vLLM vs. Full vLLM — What’s Kept, What’s Stripped Away
Here’s a clear breakdown of what nano-vLLM implements versus what it intentionally leaves out:
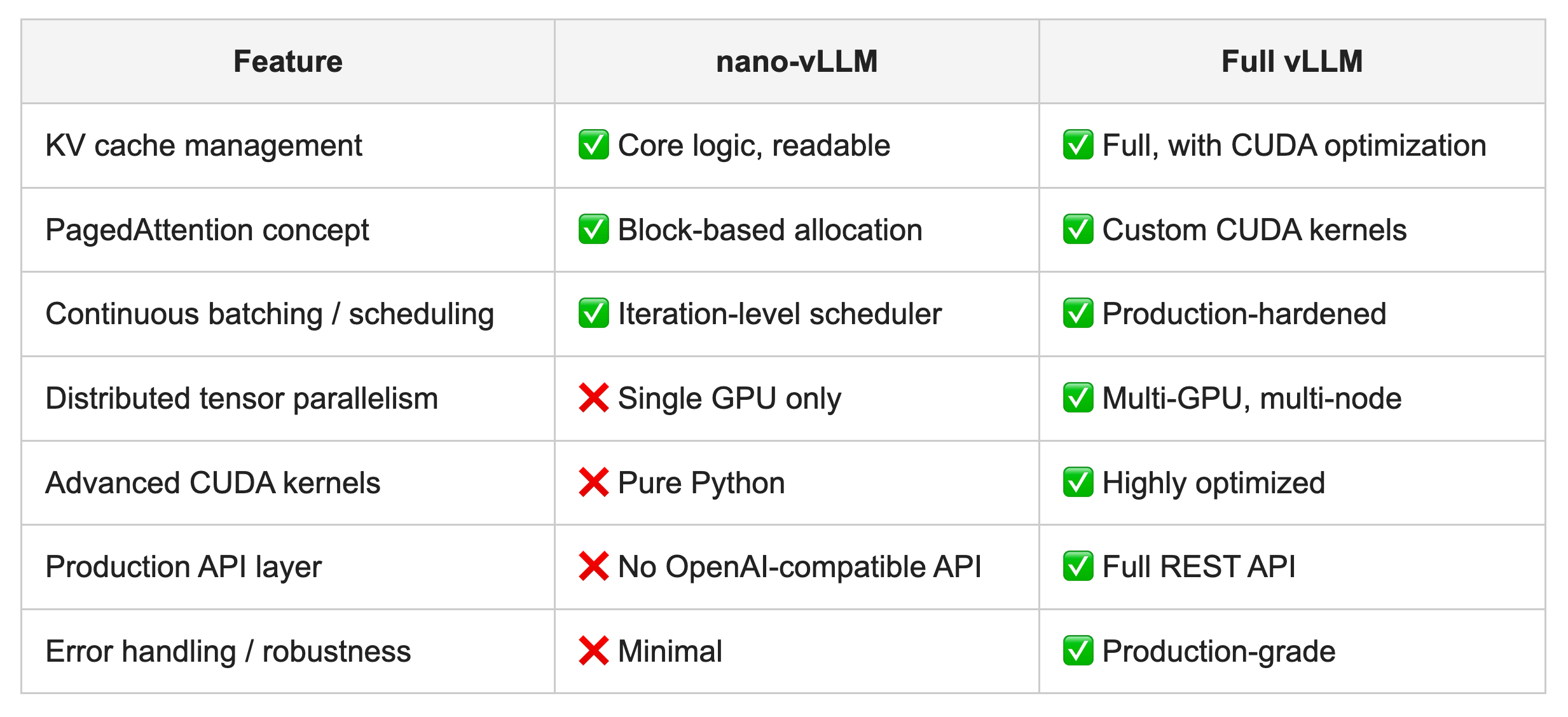
Everything nano-vLLM omits, it omits deliberately. The goal isn’t to serve a production workload — it’s to give you a clean mental model of what the full system is actually doing beneath its abstractions.
The Core Problem That Makes LLM Inference Hard
To appreciate why any of these optimizations exist, you first need to feel the pain they solve. Let’s spend a moment on why serving LLMs efficiently is genuinely, fundamentally difficult — not just a matter of throwing more GPUs at the problem.

Autoregressive Generation and the Token-by-Token Performance Trap
Modern LLMs generate text through autoregressive decoding — one token at a time, where each new token depends on every token that came before it. This sequential dependency is a fundamental architectural property of transformer models, not an implementation choice you can engineer around. Without optimization, generating a 500-token response means 500 sequential forward passes through your model.
Think of it this way: imagine writing a letter where, before adding each new word, you re-read the entire letter from the beginning to decide what word comes next. That’s essentially what naive LLM inference does on every token step. The computational cost grows with sequence length, and under load with dozens of concurrent requests, this becomes the dominant bottleneck between you and acceptable throughput.
The good news is that previously generated tokens don’t change between steps — which means there’s massive redundant computation happening on every forward pass. That redundancy is exactly what KV caching is designed to eliminate. But before we get there, there’s another layer to the problem.
Memory Pressure — Why GPU VRAM Becomes the Bottleneck
As sequence length grows, so does the memory needed to serve that request. Each token in the sequence requires storing key-value tensors across all attention layers — and those tensors live in GPU VRAM. For a model like Llama 3 8B, a single long-context request can consume several gigabytes of VRAM just for its KV cache.
Multiply that by 20, 50, or 100 concurrent users. With naive memory management, you’d pre-allocate a worst-case contiguous memory block for each request’s potential maximum sequence length — most of which sits unused for most of that request’s lifetime. GPU memory fragments, requests start competing for VRAM, and the system either crashes or starts aggressively throttling. Raw compute capacity becomes irrelevant; you’re bottlenecked on memory management, not arithmetic.
This is the insight that surprises most developers new to LLM serving: the challenge often isn’t running the model — it’s managing the memory around running the model at scale.
The Batching Dilemma — Throughput vs. Latency Tradeoffs
There’s another layer: how you group requests together. Static batching — the naive approach — groups incoming requests into fixed batches, runs the batch until every request has finished generating, then starts the next batch. This beats running requests one at a time, but it introduces a painful “head-of-line blocking” problem.
Say your batch has one request generating 2,000 tokens and five requests generating 50 tokens each. Those five short requests have to wait idle while the long request finishes. The GPU is technically busy, but you’re paying a steep latency penalty for every short request in that batch. This is the classic throughput-versus-latency tradeoff that makes static batching a poor fit for real-world LLM serving — and it sets up perfectly why continuous batching was such a meaningful innovation.
KV Caching Explained — The Biggest Win in LLM Inference
If you understand only one optimization in this entire article, make it this one. KV caching is the single highest-leverage technique in LLM inference, and nano-vLLM’s codebase is the cleanest place I’ve found to see it in action.

What Are Key-Value Pairs in the Attention Mechanism?
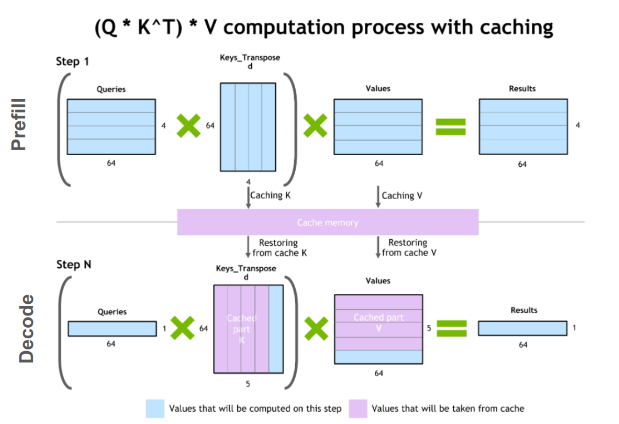
In the transformer attention mechanism, every token gets three learned projections: a query (Q), a key (K), and a value (V). During inference, each new token attends to all previous tokens by comparing its query against their keys, then uses those comparisons to weight a sum of the corresponding values. That’s how the model “looks back” at context to decide what’s relevant.
Here’s the crucial observation: once a token has been processed and its K and V tensors computed, those tensors don’t change. The key-value pairs for “The cat sat on” don’t change just because you’re now computing the next token after “on.” They’re fixed, deterministic outputs of the model’s weight matrices applied to that token’s embedding. Think of KV pairs like notes you’ve already written — without caching, you’d be rewriting those same notes from scratch before glancing at them every single time.
How KV Caching Eliminates Redundant Computation
KV caching operationalizes that observation: rather than recomputing K and V for every token in the context on every forward pass, you compute them once and store them. The next token’s forward pass only needs to compute Q, K, and V for the new token, then retrieve the cached K and V from all previous tokens. The amount of skipped computation is enormous.
Without KV caching, inference cost scales quadratically with sequence length. With it, the incremental cost of generating each new token is roughly constant, regardless of how long the context has grown. For long-form generation — multi-turn conversations, document summarization, code generation — this difference isn’t marginal. It’s the difference between a usable system and an unusable one.
Reading KV Cache Logic in nano-vLLM’s Codebase
This is where nano-vLLM earns its place. The KV cache management logic lives in just a few hundred lines — you can find the allocation logic, the store-and-retrieve pattern, and the interaction with the scheduler all in one focused read. Here’s a simplified illustration of the pattern you’ll find:
# Simplified KV cache store-and-retrieve pattern (illustrative)
class KVCache:
def __init__(self, num_layers, max_blocks, block_size, head_dim):
# Pre-allocate cache tensors for all layers
self.cache = torch.zeros(
num_layers, 2, max_blocks, block_size, head_dim
)
def store(self, layer_idx, block_idx, position, key, value):
self.cache[layer_idx, 0, block_idx, position] = key
self.cache[layer_idx, 1, block_idx, position] = value
def retrieve(self, layer_idx, block_indices):
keys = self.cache[layer_idx, 0, block_indices]
values = self.cache[layer_idx, 1, block_indices]
return keys, values
You can read this pattern, understand it fully, and trace how it interacts with the attention computation in about 20 minutes. Try doing the equivalent in vLLM’s production codebase — you’ll be context-switching across multiple modules, CUDA bindings, and async abstractions before you find the same idea. Reading clean code is a skill-building activity, and nano-vLLM is genuinely worth reading.
PagedAttention — Borrowing From Operating Systems to Fix Memory Fragmentation
KV caching solves redundant computation beautifully. But it introduces a new challenge: as you scale to many concurrent requests with different sequence lengths, managing all those cached tensors in GPU memory becomes its own mess. Enter PagedAttention.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
The Memory Fragmentation Problem With Naive KV Caching
When you naively implement KV caching for multiple concurrent requests, you typically allocate a contiguous block of GPU memory for each request’s cache — sized for the maximum possible sequence length that request might reach. It’s the safe, simple approach. It’s also brutally wasteful.
A request that generates 50 tokens but was allocated memory for 2,048 tokens wastes 97.5% of its reserved VRAM. Multiply that across dozens of concurrent requests and you have severe memory fragmentation — large pools of technically allocated but functionally unused GPU memory that can’t be handed to new requests. Early operating systems had exactly this problem with RAM, and the solution OS designers landed on is the same one vLLM’s research team applied to transformer inference.
PagedAttention — Virtual Memory for GPU Attention
PagedAttention fixes memory fragmentation by allocating KV cache memory in fixed-size blocks — analogous to memory pages in an OS — rather than large pre-sized contiguous chunks. Each block holds KV pairs for a fixed number of tokens (say, 16 tokens). When a request needs more KV cache space, it gets another block — and that block doesn’t need to be physically adjacent to the previous one.
A block table maps each request’s logical sequence of blocks to their physical locations in GPU memory, exactly as a page table maps logical addresses to physical RAM. The attention computation references block table entries to find its KV data rather than assuming contiguous memory. The original vLLM paper (Source: https://arxiv.org/abs/2309.06180) showed this achieves dramatically higher GPU memory utilization than prior approaches — sometimes enabling 2–4x more concurrent requests on the same hardware.
How nano-vLLM Makes PagedAttention Readable
In nano-vLLM, PagedAttention is implemented in plain Python — you can find the block allocator managing a free-list of physical blocks, the per-request block table tracking logical-to-physical mappings, and the attention function referencing that block table during computation. Here’s a simplified illustration:
# Simplified block table lookup (illustrative)
class BlockTable:
def __init__(self):
self.logical_to_physical = {} # logical block idx -> physical block idx
def append_block(self, logical_idx, physical_idx):
self.logical_to_physical[logical_idx] = physical_idx
def get_physical_blocks(self, logical_indices):
return [self.logical_to_physical[i] for i in logical_indices]
Compare this to navigating the same concept in vLLM’s production codebase, where block management is interleaved with CUDA kernel dispatch, async scheduling, and distributed memory coordination. In nano-vLLM, the idea is exposed cleanly — you can hold the entire mechanism in your head at once. That’s a rare thing when studying systems software.
Continuous Batching and Request Scheduling — Keeping the GPU Busy
KV caching handles redundant computation. PagedAttention handles memory fragmentation. Now let’s talk about the third pillar: keeping the GPU as busy as possible by rethinking when requests enter and exit the system.

{kind=link}
Why Static Batching Leaves Performance on the Table
Static batching is the intuitive approach: collect a group of requests, process them together, wait until every request has finished generating, then load the next batch. Simple, predictable, and genuinely better than one-at-a-time processing. But it has a serious flaw.
Real workloads have wildly different output lengths. One user wants a one-sentence summary; another wants a 1,000-word essay. In static batching, the short requests finish early and sit idle waiting for the long request to complete before the batch turns over.
This is head-of-line blocking — the longest request holds everyone else hostage. It’s like a restaurant that only seats a new party after every single diner at the current table has finished, paid, and left — even if four of them have been done for 20 minutes and are just waiting on the one person who ordered dessert. You’d leave that restaurant.
Continuous Batching — Iteration-Level Scheduling
Continuous batching, first described in the Orca paper (Source: https://www.usenix.org/conference/osdi22/presentation/yu), solves head-of-line blocking by changing scheduling granularity from batch completion to individual decoding steps. At each token generation step — each forward pass — the scheduler checks whether any running requests just produced their final token. If they did, their KV cache blocks are freed and new waiting requests immediately slot into the available capacity.
The GPU never stops to wait for a full batch to clear. New requests flow in as space opens up, continuously. The result is dramatically higher GPU utilization, especially under mixed workloads — exactly the conditions you’ll face in production. Continuous batching is one of the main reasons modern serving systems can sustain throughput levels that would have seemed impossible with earlier infrastructure.
Tracing the Scheduler in nano-vLLM
The scheduler is one of the most instructive components to trace in nano-vLLM because it’s where KV caching, PagedAttention block management, and batching logic all converge. The scheduler maintains a waiting queue of incoming requests, a running set of actively decoding requests, and a loop that fires on every decoding step.
On each step, it checks which running requests have finished, frees their blocks back to the allocator, and promotes waiting requests into the running set as block capacity allows. Here’s the conceptual shape of that loop:
# Simplified scheduler step (illustrative)
def schedule_step(self):
# 1. Check for completed requests and free their blocks
for request in self.running:
if request.is_finished():
self.block_allocator.free(request.block_table)
self.running.remove(request)
# 2. Promote waiting requests into running set
while self.waiting and self.block_allocator.has_capacity():
next_request = self.waiting.pop(0)
next_request.block_table = self.block_allocator.allocate()
self.running.append(next_request)
# 3. Return current running set for the next decode step
return self.running
You can trace this loop, understand every line, and see exactly how it interacts with the block allocator and the model’s forward pass. The mental model you build here transfers directly to vLLM’s production scheduler — which does the same things, just with significantly more machinery around them. That’s the real payoff of using nano-vLLM as a learning sandbox.
Frequently Asked Questions
Q: Is nano-vLLM actually usable for serving models in production? No — and that’s intentional. nano-vLLM lacks the distributed parallelism, optimized CUDA kernels, production API layer, and robustness features that real serving requires. Think of it like a teaching hospital simulator: it builds real skills, but you wouldn’t perform surgery on it. For production open source LLM deployment, use full vLLM, TGI, or TensorRT-LLM.
Q: What models can I run with nano-vLLM for learning purposes? nano-vLLM supports standard HuggingFace-compatible transformer models on a single GPU. It works best with smaller models (7B–13B parameters) where you can observe the behavior without massive hardware requirements. The focus is on reading and understanding the code, not benchmarking outputs.
Q: How long does it actually take to read through the nano-vLLM codebase? A focused developer can trace the core scheduling and caching logic in 2–4 hours. The full ~1,000-line codebase can be read meaningfully in a day. Compare that to vLLM’s 100,000+ lines — there’s no realistic equivalent study session for the production codebase.
Q: Does understanding nano-vLLM actually help with using full vLLM in production? Significantly, yes. Once you have a clear mental model of how KV cache blocks are allocated and freed, why continuous batching improves throughput, and what PagedAttention’s block table is doing — debugging vLLM configuration issues, tuning --max-num-batched-tokens, or understanding why certain workloads cause memory pressure becomes far more intuitive.
Q: Where does nano-vLLM fit relative to reading the original vLLM paper? They’re complementary, not alternatives. The original vLLM paper (Source: https://arxiv.org/abs/2309.06180) gives you the theoretical framing and motivation. nano-vLLM gives you the implementation intuition — how these ideas actually translate into code. Reading the paper first, then tracing nano-vLLM, then skimming full vLLM’s relevant modules is probably the highest-ROI learning path available.
Conclusion
Here’s the uncomfortable truth most LLM deployment tutorials skip: you can use vLLM successfully for months without understanding what it’s actually doing. And then one day something breaks in a way the documentation doesn’t explain, or a performance problem surfaces that you can’t debug without knowing what’s happening inside the engine — and suddenly the black box is a liability.
nano-vLLM exists to prevent that moment from blindsiding you. A few hours with its ~1,000 lines of clean, intention-revealing Python will build a genuine mental model of KV caching, PagedAttention, and continuous batching that no amount of high-level blog posts can replicate. The core insight this nano vLLM tutorial has tried to surface is simple: nano-vLLM is not a lightweight production tool — it’s a learning accelerator, and knowing how to use it is far more valuable than it might first appear.
The mental models you build here transfer directly to every production-grade open source LLM deployment tool you’ll encounter: vLLM, TGI, TensorRT-LLM, and whatever comes next. The LLM inference optimization techniques that make them fast are the same ones you can now trace in a few hundred lines of readable code. That’s a real edge for any ML engineer who wants to move from using these tools to truly understanding them.
Ready to open the black box?
Clone the nano-vLLM repository (https://github.com/GeeeekExplorer/nano-vllm), open the scheduler and KV cache modules, and trace one full decoding step end-to-end. It’ll take you an afternoon. It’ll pay off every time you touch an LLM serving system for the rest of your career.
Sources
https://miro.medium.com/v2/resize:fit:1400/1*-ceG6v7SbJHTivsnUsJmPQ.jpeg
https://developer-blogs.nvidia.com/wp-content/uploads/2023/11/key-value-caching_.png
https://miro.medium.com/v2/resize:fit:1200/1*FqKiqclKkgSmlbY3qCxrig.png
💡 Want to share your work on my socials with my 15k+ audience? If you build a project you are excited about, I will be too. Trust me! I love seeing people build cool stuff. To share it, you can contact me here.
Did you enjoy this post? Here are some other AI Agents posts you might have missed:
KV Caching and Speculative Decoding
A deep dive into Quantization: Key to Open Source LLM Deployments
Agents are here and they are staying
How Agents Think
Memory – The Agent’s Brain
Agentic RAG Ecosystem
Multimodal Agents
Scaling Agents: Architectures with Google ADK, A2A, and MCP
Fully Functional Agent Loop
Ready to take it to the next level?
Check out my AI Agents for Enterprise course on Maven and be a part of something bigger and join hundreds of builders to develop enterprise level agents.

Use this link to get $201 OFF!
You’re receiving this email because you’re part of our mailing list—and you’ve attended, registered for, or been invited to our MAVEN events. These emails are the only way to reliably receive updates from us. We don’t spam or sell your information. If you prefer not to receive our messages, simply unsubscribe below and we’ll respect your wishes.
This is a great breakdown of the “production gap” most engineers hit when moving from models to real-world systems, especially around latency, memory, and batching tradeoffs. I like how nano-vLLM is positioned as a learning tool to actually understand KV caching, PagedAttention, and scheduling instead of treating them like black boxes
PagedAttention clicked for me reading a simplified version like this. Running a 35B model locally on consumer hardware, the memory fragmentation problem shows up in practice - context fills unevenly and the naive approach wastes headroom. The "production systems are impenetrable" point is accurate.
I've dug into vLLM source a few times trying to understand something specific and gave up. A 1,000-line version is a better mental model builder than the full codebase for someone who uses these engines but doesn't contribute to them. Continuous batching is probably where most of the practical impact is for multi-user serving. Not sure if this generalizes, but for solo deployment the KV caching piece was what actually changed my config decisions.