
KV Caching and Speculative Decoding
Why you should know these concepts and the role they play



👋 Hi everyone, I am Hamza.
Welcome to Edition #27 of a newsletter that 14,000+ people around the world actually look forward to reading.
We’re living through a strange moment: the internet is drowning in polished AI noise that says nothing.
This isn’t that. You’ll find raw, honest, human insight here, the kind that challenges how you think, not just what you know. Thanks for being part of a community that still values depth over volume.
🎓 Want to up skill in AI?
Join the next cohort of my Agent Engineering Bootcamp (Developers Edition) April 8
Watch the free 4-session Agent Bootcamp playlist on YouTube
Two AI Optimization Techniques That Transform Language Model Speed
Modern large language models face a simple problem: they’re too slow for real-time use. Traditional inference methods force models to recalculate the same computations repeatedly and generate text one token at a time. This creates bottlenecks that get worse with longer conversations.
Two techniques are changing this. KV Cache stores previous computations in memory so the model doesn’t repeat the same work. Speculative Decoding uses a small, fast model to generate multiple tokens at once, then verifies them with the full model. Together, they can speed up AI responses by 10x or more.
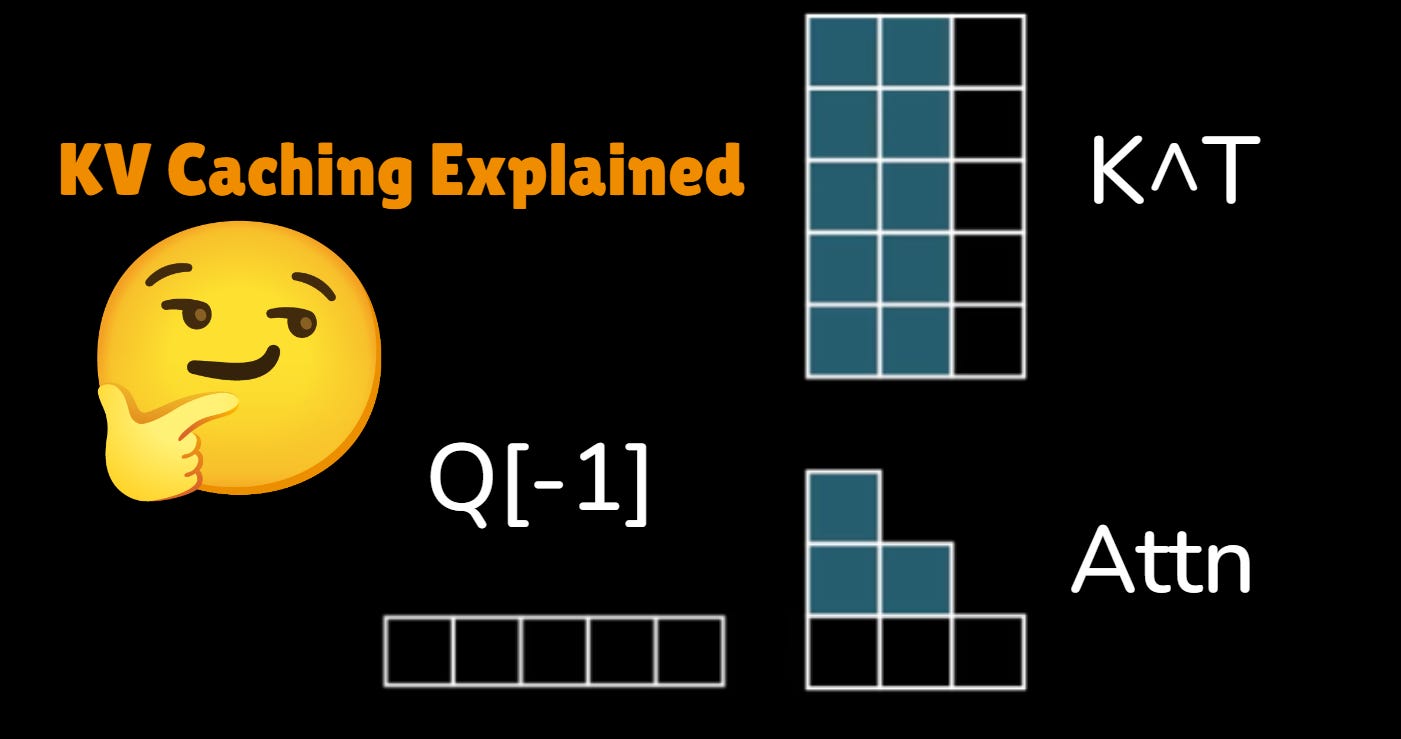
KV caching visual overview (quick anchor before we dive into mechanics).
These aren’t theoretical improvements. Companies are using them now to cut costs and improve user experience.
How KV Cache Works
The Core Problem
When a language model generates text, it uses an attention mechanism to understand which previous words matter for the next word. Traditional inference recalculates these attention weights for every single token, even though most of the computation stays the same.
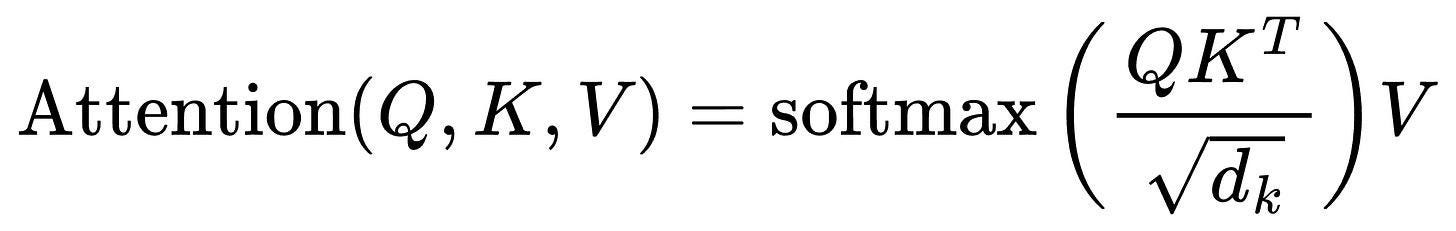
Attention at a glance: Attention(Q, K, V) = softmax(QKᵀ/√dₖ) V
Source:

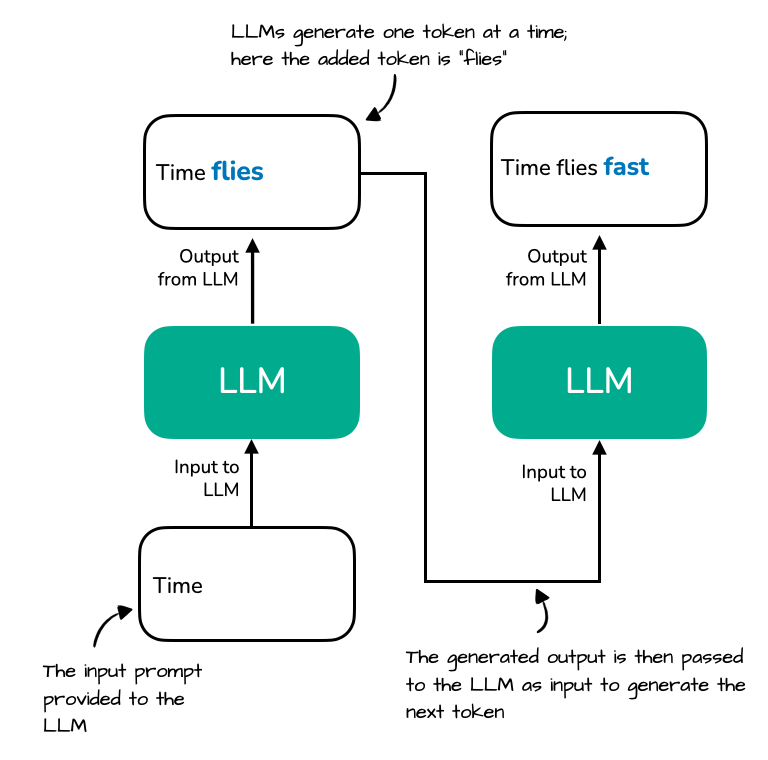
Autoregressive decoding reprocesses the growing prefix at each step (why decoding slows down).
Source:

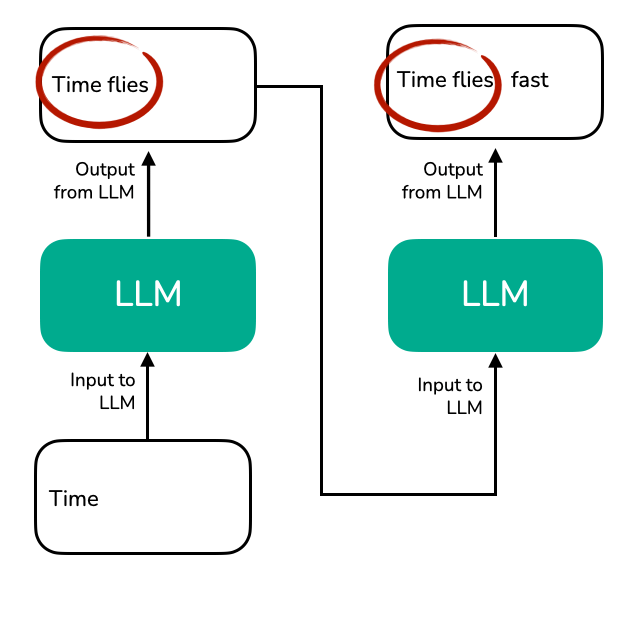
Redundancy across decoding steps: most of the prefix is repeated work.
Source: https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms
For a conversation with 1,000 previous tokens, the model performs 1,000 × 1,000 = 1,000,000 operations for each new word. This quadratic complexity makes longer conversations exponentially slower.
The Solution
KV Cache stores the Key and Value matrices from previous tokens. When generating a new token, the model retrieves these stored values instead of recalculating them.
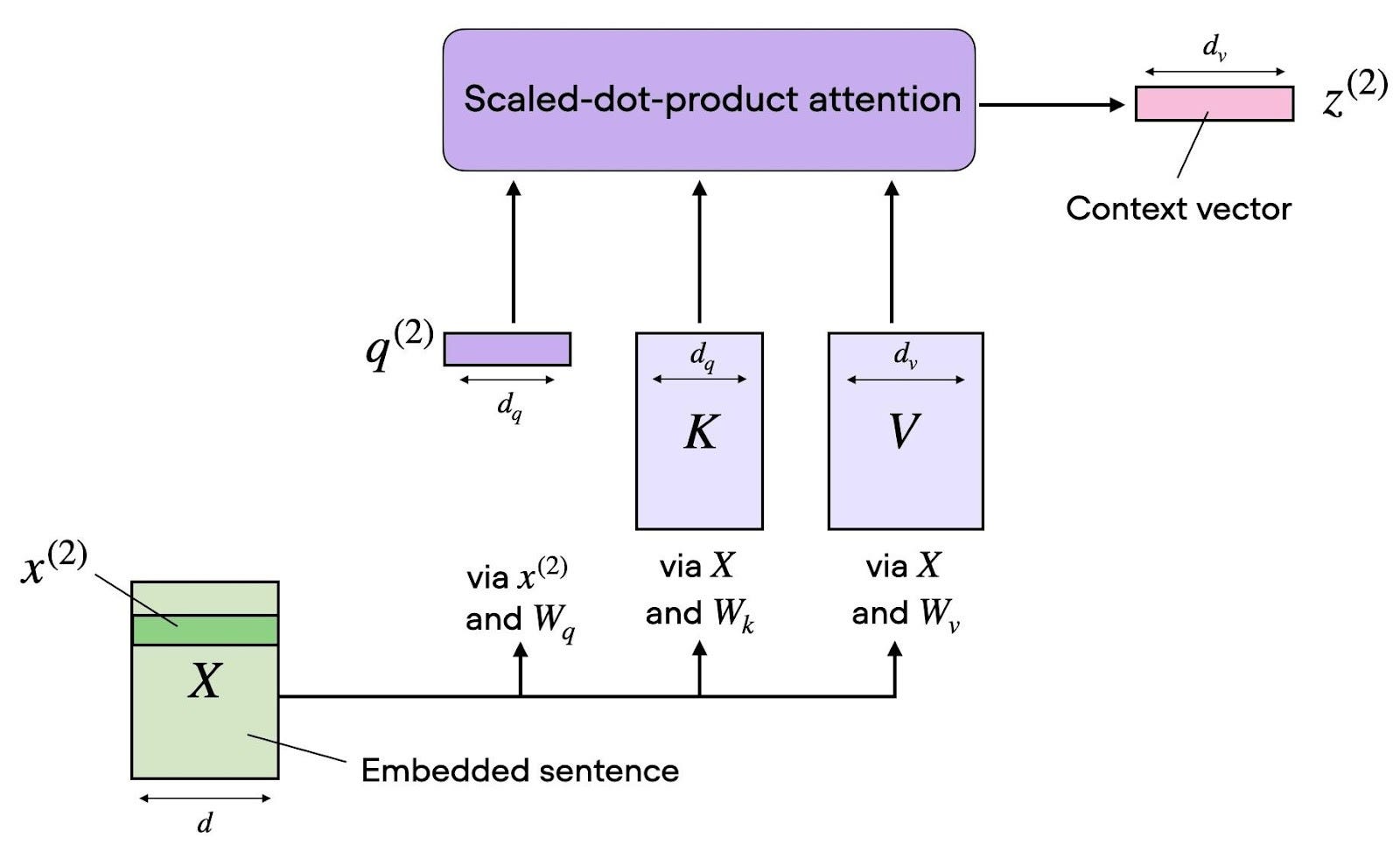
Inside self-attention: Q/K/V projections feed the attention computation (KV caching reuses K and V).
Source: https://blog.gaurav.ai/2025/08/05/kv-caching-kv-sharing/
This reduces 1,000,000 operations down to 1,000 operations per token. The attention mechanism goes from O(n²) to O(n) for each new token.
Here’s what happens step by step:
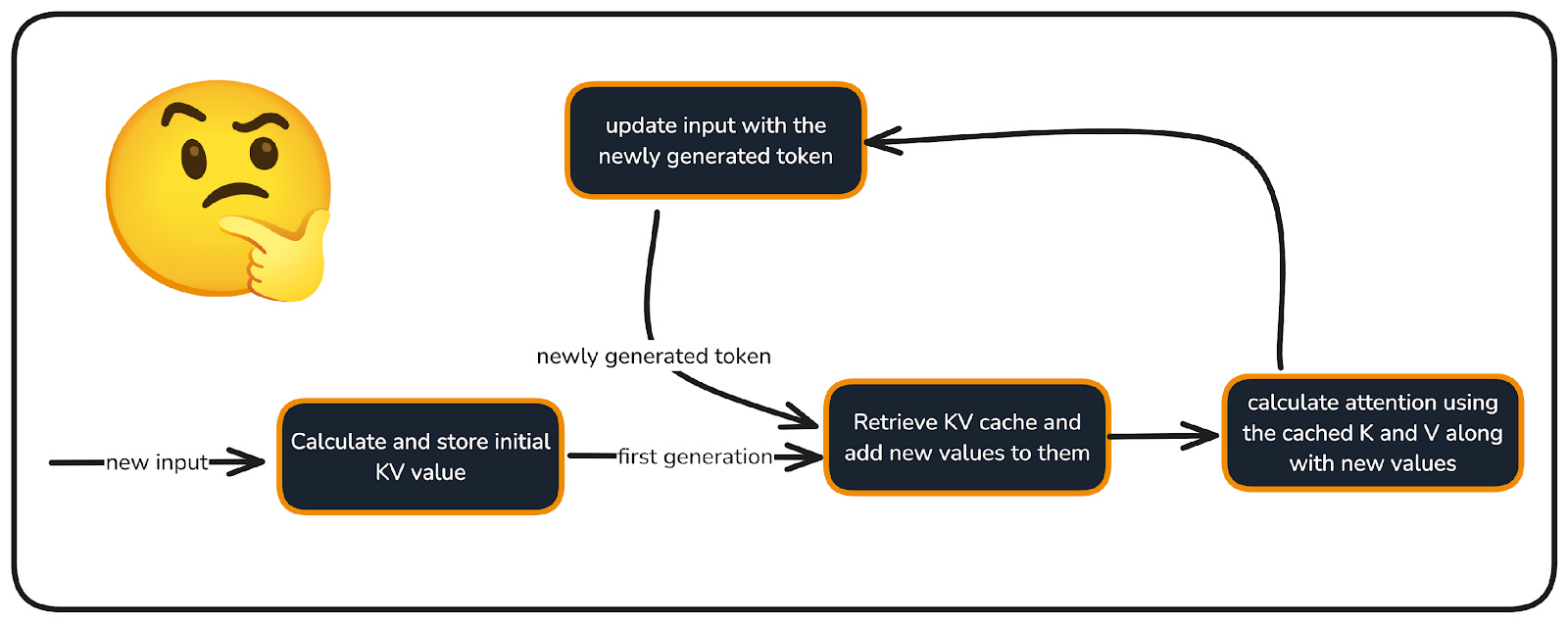
KV caching loop: store K/V once, append new K/V each step, and reuse cached tensors for attention.
Source: https://huggingface.co/blog/not-lain/kv-caching
The system retrieves stored K and V matrices from cache memory
It computes only the new Q, K, V vectors for the current token
It combines new values with cached values
It performs the attention calculation
It updates the cache with the new token’s K, V values
Real Performance Gains
A financial services company processing 15,000 regulatory documents daily saw a 67% reduction in response time after implementing KV Cache. They analyzed documents in real time instead of waiting hours.
The benefits increase with sequence length. Short sequences see 40-50% speedups. Long conversations with thousands of tokens can be 3x faster or more.
Memory usage increases by 10-20% of model parameters, which is a reasonable trade-off for the speed gains.
How Speculative Decoding Works
The Draft-and-Verify Method
Normal text generation is sequential. The model generates one token, then uses that token to generate the next one. You can’t parallelize this process.
Speculative Decoding breaks this pattern. A small, fast draft model generates multiple token candidates. Then the large target model verifies all of them at once in a single forward pass.
The draft model might be 10-100x faster than the target model. It doesn’t need to be perfect. It just needs to generate reasonable candidates that the target model can verify quickly.
The Process
Draft Generation Phase
The small model generates k candidate tokens rapidly. For example, it might propose the next 5-10 tokens in a sentence.
Batch Verification
The large model processes all k candidates simultaneously. This batch processing uses GPU parallelization to verify multiple tokens with minimal overhead compared to processing one token.
Acceptance Decision
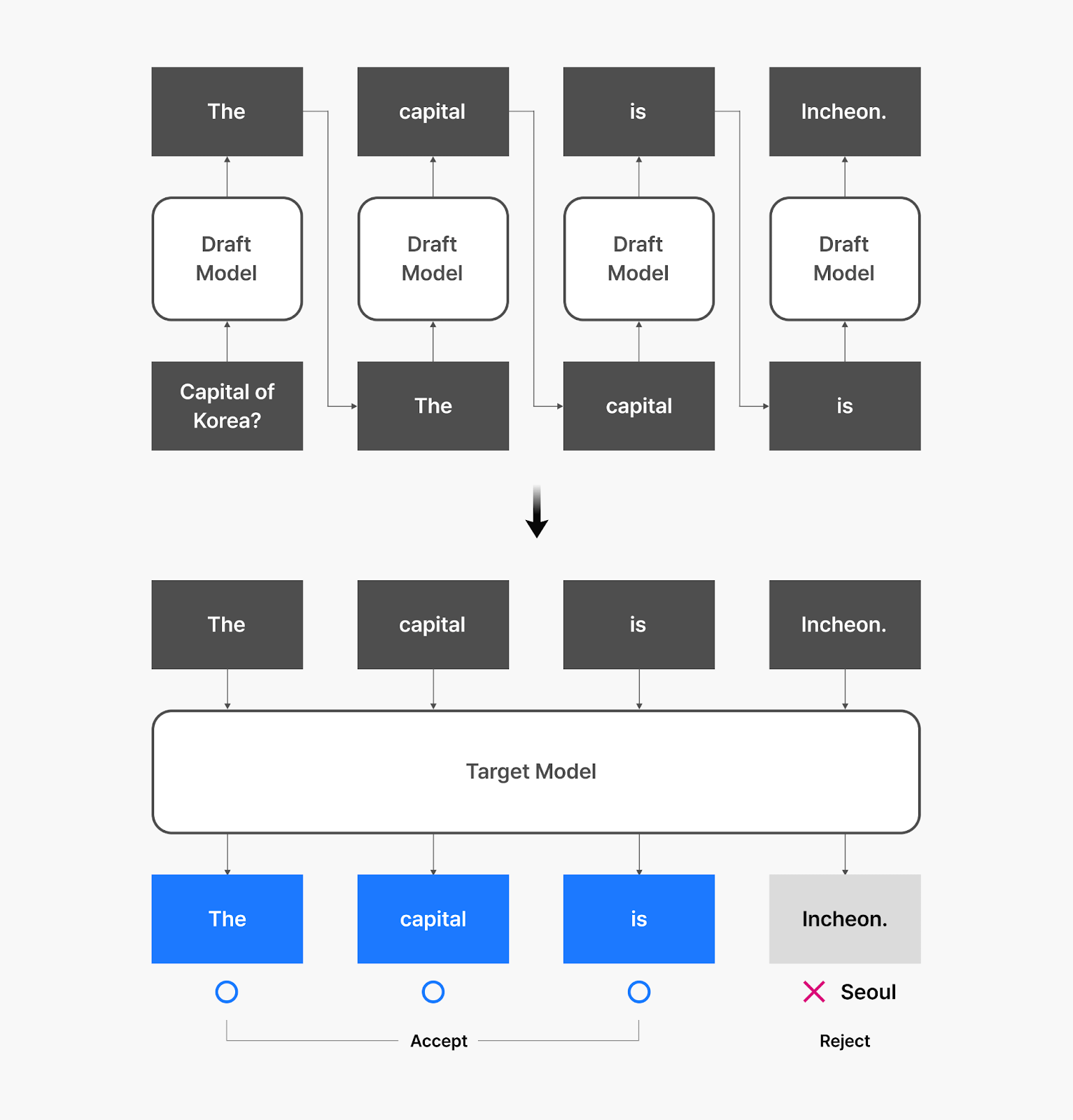
Source:https://clova.ai/en/tech-blog/breaking-the-speed-barrier-how-we-implemented-speculative-decoding-for-hyperclova-x?utm_source=chatgpt.com
An algorithm compares the draft model’s probabilities with the target model’s probabilities. It accepts tokens that meet the quality threshold and rejects the rest.
If all tokens are accepted, the system just generated multiple tokens in roughly the time it normally takes to generate one. If some are rejected, the system falls back to standard generation for those positions.
Adaptive Window Sizing
The system adjusts how many tokens the draft model generates based on acceptance rates. High acceptance rates increase the window size. Low acceptance rates decrease it.
Production Results
A major cloud provider implemented Speculative Decoding for their conversational AI platform with these results:
7.2x average speedup in chatbot responses
45% reduction in GPU resource consumption
$2.3M annual cost savings
Zero degradation in customer satisfaction scores
They used a 1.5B parameter draft model with a 175B parameter target model.

Source: https://www.together.ai/blog/customized-speculative-decoding
Comparing the Two Techniques
Different Approaches
KV Cache removes redundant computations within the attention mechanism. It’s a straightforward optimization that works with existing model architecture.
Speculative Decoding changes how tokens are generated. It requires two models working together and adds architectural complexity.
Performance Patterns
Speed Improvements:
KV Cache: 1.5-3x typical gains, more for longer sequences
Speculative Decoding: 3-10x potential gains
Combined: Over 10x total speedup possible
Memory Requirements:
KV Cache: 10-20% overhead, grows with sequence length
Speculative Decoding: Higher baseline but fixed overhead
Combined: Requires careful memory management
Implementation Complexity:
KV Cache: Low to medium, straightforward to add
Speculative Decoding: High, needs sophisticated coordination
When to Use Each
Use KV Cache for:
Long documents or conversations
Extended context windows
Applications with growing conversation history
Memory-efficient deployments
Legal document processing systems report 78% latency reduction with KV Cache. Customer service platforms maintain sub-second response times even after hundreds of exchanges.
Use Speculative Decoding for:
Applications requiring maximum speed
Interactive real-time experiences
Batch processing workflows
Latency-critical deployments
Educational platforms report 340% increases in student engagement with near-instantaneous AI responses. Financial trading platforms achieve sub-100ms response times for real-time market analysis.
Implementation Challenges
KV Cache Challenges
Memory Management
You need adaptive sizing strategies. Cache size must balance hit rates against memory consumption, especially when sequence lengths vary.
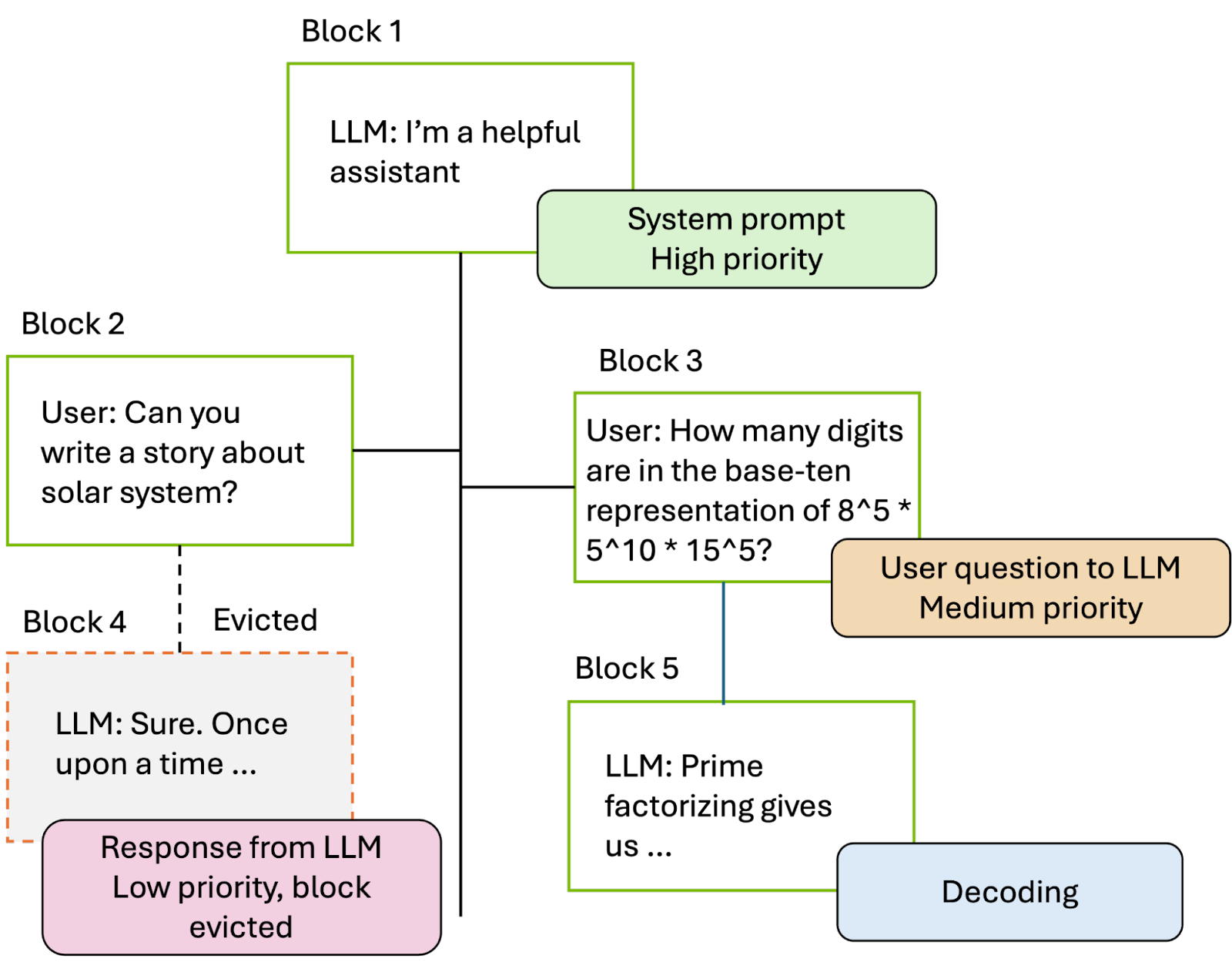
Production reality: priority-based eviction helps keep reusable prompt blocks in cache longer.
Source: https://developer.nvidia.com/blog/introducing-new-kv-cache-reuse-optimizations-in-nvidia-tensorrt-llm/
Production systems use automated cache eviction policies based on usage patterns. They also need monitoring systems that track cache efficiency in real time.
Cache Invalidation
The cache must stay consistent when models update or conversation context shifts. Systems need versioning and validation mechanisms to detect and correct inconsistencies.
Speculative Decoding Challenges
Model Coordination
You need continuous calibration to maintain optimal acceptance rates. If the draft model generates poor candidates, the system wastes computation on rejected tokens.
Organizations use automated evaluation pipelines with continuous performance monitoring. They tune parameters based on real-time feedback.
Resource Management
Managing two models requires sophisticated orchestration. The system must allocate computational resources between draft and target models based on workload and hardware constraints.
Advanced implementations use adaptive resource allocation with predictive scaling based on usage patterns.
Quality Assurance
Both techniques need comprehensive validation. Automated testing pipelines evaluate output quality across diverse use cases.
A/B testing frameworks compare optimized and standard inference across metrics like semantic coherence, factual accuracy, and task performance. Real-time monitoring tracks latency, throughput, memory usage, and quality scores.
Failure recovery mechanisms automatically revert to standard inference when optimizations encounter errors. This ensures reliability while enabling aggressive optimization.
Real-World Applications
Customer Service
A telecommunications company handles 2 million daily customer interactions. They implemented both KV Cache and Speculative Decoding with a 7B parameter draft model and 175B parameter target model.
Results:
87% reduction in average response time (4.8s to 0.7s)
23% increase in customer satisfaction
34% reduction in call abandonment
$1.8M annual savings
The system maintains conversation coherence across extended support sessions with consistent sub-second response times.
Code Generation
GitHub Copilot and similar tools use these optimizations to provide real-time code completion. They need sub-100ms response times to avoid disrupting developer flow.
A major software company’s internal platform supports 12,000 developers:
67% improvement in code completion speed
94% acceptance rate for suggestions
Real-time code review and documentation generation
Content Creation
News organizations use optimized AI to generate draft articles within 30 seconds of breaking events. A major news outlet processes 500+ breaking news events daily with a 78% reduction in time-to-publish.
Gaming platforms use optimization for dynamic narrative generation. One studio supports 100,000 concurrent players with personalized storylines. They achieved 5.2x improvement in narrative generation speed and 156% increase in player engagement.
Specialized Industries
Financial Services
A hedge fund’s system delivers investment insights within seconds of market events. They achieved 94% accuracy in market sentiment analysis while reducing analysis time from hours to minutes.
Healthcare
A hospital network processes 25,000 patient interactions daily. Medical staff spend 89% less time on documentation while improving accuracy and completeness.
Legal
A law firm processes 2,000+ legal documents daily with 71% reduction in initial review time. Lawyers focus on high-level strategy while AI handles routine document processing.
Implementation Strategy
Phase 1: Foundation (Weeks 1-4)
Establish baseline performance metrics.
Set up comprehensive monitoring infrastructure.
Develop testing frameworks for quality validation.
Conduct technical feasibility assessments and prepare infrastructure for optimization deployment.
Phase 2: Pilot (Weeks 5-12)
Deploy optimizations in controlled environments with limited traffic.
Run extensive A/B testing comparing optimized and standard inference.
Tune parameters based on real-world data.
Develop operational procedures for monitoring and maintenance.
Phase 3: Production (Weeks 13-20)
Implement gradual rollout with continuous monitoring and automatic fallback.
Continue fine-tuning based on production data.
Run comprehensive cost-benefit analysis to validate optimization effectiveness.
Phase 4: Advanced Optimization (Weeks 21+)
Explore combined implementation of multiple techniques.
Develop custom optimizations for specific use cases.
Build sophisticated monitoring and automated optimization systems that continuously improve based on usage patterns.
Sample Implementation
class OptimizedInferenceEngine:
def __init__(self, target_model, draft_model, cache_config):
self.target_model = target_model
self.draft_model = draft_model
self.kv_cache = DynamicKVCache(cache_config)
self.memory_pool = AdaptiveMemoryPool()
self.speculation_window = AdaptiveWindowSizer()
self.performance_monitor = RealTimeMonitor()
def generate_optimized(self, prompt, max_length):
# Initialize KV cache with conversation context
cached_kv = self.kv_cache.get_or_create(prompt)
# Calculate optimal speculation window
window_size = self.speculation_window.calculate_optimal_size(
cache_efficiency=cached_kv.hit_rate,
available_memory=self.memory_pool.available_capacity,
target_latency=self.performance_monitor.target_latency
)
return self.speculative_decode_with_cache(
prompt, cached_kv, window_size, max_length
)
Future Developments
New Optimization Approaches
Researchers are designing transformer architectures specifically for efficient inference. Sparse attention mechanisms and hierarchical processing structures reduce computational requirements by 60-80% while maintaining model capability.
Quantum-classical hybrid processing shows promise for exponential speedups in attention weight calculation, though practical applications are years away.
Neuromorphic computing explores brain-inspired architectures for ultra-low-power inference, especially in edge computing environments.
Hardware Evolution
Custom silicon is being designed specifically for KV caching operations and speculative decoding workflows. Major semiconductor companies are developing inference-optimized chips that could deliver 10-100x improvements over general-purpose GPUs.
New memory systems are being developed specifically for AI workloads, with high-bandwidth memory optimized for KV cache storage.
Industry Adoption
Major cloud providers now offer optimization techniques as managed services. AWS, Google Cloud, and Microsoft Azure are integrating KV Cache and Speculative Decoding into their AI platforms.
Open source frameworks like Hugging Face Transformers, vLLM, and TensorRT make these optimizations accessible to smaller organizations.
Self-Optimizing Systems
Researchers are developing AI systems that automatically optimize their own inference performance through experience and learning. Early research shows AI systems improving their own inference efficiency by 40-60% through automated optimization discovery.
These adaptive systems could eliminate manual parameter tuning by continuously adjusting optimization strategies based on usage patterns, hardware characteristics, and performance objectives.
Reflections
KV Cache and Speculative Decoding have transformed what’s possible with large language models. KV Cache eliminates redundant computations by storing previous calculations. Speculative Decoding accelerates generation by using a small model to propose tokens that a large model verifies in parallel.
Combined, these techniques can achieve 10x or greater speedups while maintaining output quality. This enables real-time AI applications that were previously too slow for production use.
The business impact is clear. Organizations report:
40-70% reduction in infrastructure costs
Improved user satisfaction from faster responses
New capabilities in real-time customer service, code generation, and content creation
Competitive advantages through superior AI performance
Success requires careful implementation. Start with baseline metrics and monitoring. Deploy in controlled environments. Test extensively. Roll out gradually with automatic fallback systems.
The techniques continue to evolve. Future developments in hardware, architecture, and self-optimizing systems promise even greater improvements. Organizations that master these optimizations now will be positioned to capitalize on future advances.
For any production AI system where speed matters, these optimizations are no longer optional. They’re essential for delivering the performance users expect and the efficiency businesses require.
Did you enjoy this post? Here are some other AI Agents posts you might have missed:
A deep dive into Quantization: Key to Open Source LLM Deployments
Agents are here and they are staying
How Agents Think
Memory – The Agent’s Brain
Agentic RAG Ecosystem
Multimodal Agents
Scaling Agents: Architectures with Google ADK, A2A, and MCP
Fully Functional Agent Loop
Ready to take it to the next level?
Check out my AI Agents for Enterprise course on Maven and be a part of something bigger and join hundreds of builders to develop enterprise level agents.

Use this link to get $201 OFF!
You’re receiving this email because you’re part of our mailing list—and you’ve attended, registered for, or been invited to our MAVEN events. These emails are the only way to reliably receive updates from us. We don’t spam or sell your information. If you prefer not to receive our messages, simply unsubscribe below and we’ll respect your wishes.
 | A guest post by
|
 | A guest post by
|