
DeepSeek V4 architecture deep dive
The open-weights frontier has a new contender. This time, the architectural details are too significant to benchmark on basic ones

👋 Hi everyone, I am Hamza. I have 18 years of building large scale ecosystems and I teach at UCLA and MAVEN, and founder of Traversaal.ai.
Welcome to Edition #36 of a newsletter that 15,000+ people around the world actually look forward to reading.
We’re living through a strange moment: the internet is drowning in polished AI noise that says nothing. This isn’t that. You’ll find raw, honest, human insight here, the kind that challenges how you think, not just what you know. Thanks for being part of a community that still values depth over volume.
🎓 Want to master frontier AI Engineering?

Build production-scale multi-agent ecosystems using Google ADK, MCP, and Claude Code Harness. Learn to solve the KV cache pressure of 1M-token contexts by implementing CSA/HCA hybrid attention and FP4 quantization. Ensure reliability with rigorous evals and observability to manage the consistency of complex agentic chains
Join the next cohort of my Agent Engineering Bootcamp (Developers Edition) May 30th (15% discount)
Watch the free 4-session Agent Bootcamp playlist on YouTubet on YouTube
DeepSeek V4 Architecture Comparison: MoE Design, Attention Mechanisms, and How It Stacks Up Against V3, Claude Opus, and OpenAI
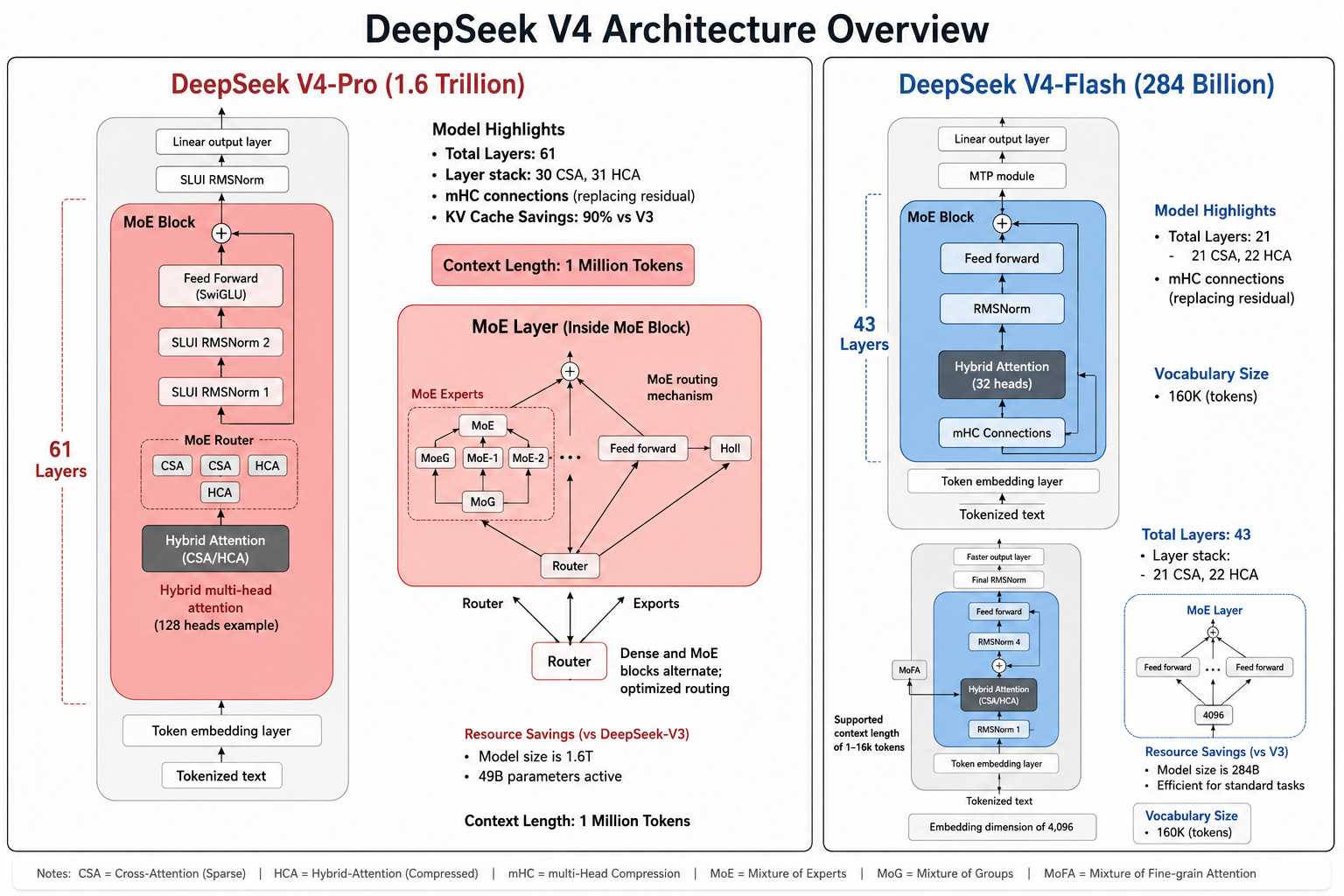
DeepSeek V4 is a high-performance open-weights artificial intelligence model that features a massive 1.6 trillion parameter architecture.
It highlights the use of a Mixture-of-Experts (MoE) design, which allows the model to activate only a small fraction of its total parameters during use to maintain cost-efficiency.
A major innovation detailed is the hybrid attention system, combining two distinct compression methods to manage an expansive one-million-token context window with minimal memory requirements.
The sources contrast two versions, the powerful V4 Pro and the agile V4 Flash, to help technical architects choose the right size for their specific hardware and speed needs.
By offering architectural transparency, the text positions these models as competitive, auditable alternatives to closed-source options like Claude and OpenAI.
This article serves as a technical guide for engineers looking to deploy frontier-level AI on their own infrastructure.
⚠️ Image Disclaimer & Notes
This diagram is a conceptual reconstruction of the reported DeepSeek V4 architecture based on publicly available technical discussions, community analysis, and early implementation references.
Some low-level implementation details, including routing internals, layer distributions, tokenizer specifications, and naming conventions may differ from the final official release.
The figure is intended for educational and illustrative purposes rather than as an official DeepSeek architecture diagram.
Introduction: Why architecture-level analysis of DeepSeek V4 can no longer be deferred
As I have been reading about DeepSeek v4, most published stays at the benchmark surface: leaderboard positions, MMLU scores, MATH pass rates, and cost-per-million-token comparisons that tell you what the model produces but almost nothing about how it produces it.
For product managers and casual evaluators, that framing is fine. For senior ML engineers and technical architects making infrastructure commitments that will govern production workloads for the next eighteen to twenty-four months, it is dangerously incomplete.
The choice between DeepSeek V4 Pro (1.6 trillion total parameters) and DeepSeek V4 Flash (284 billion total parameters) is not simply a throughput-versus-capability trade-off.
The two variants have divergent attention topologies, distinct KV cache pressure profiles, and fundamentally different memory access patterns with cascading effects on GPU memory budgeting, batching strategy, and multi-agent serving infrastructure.
An organization that selects V4 Pro for a long-context document processing pipeline and then discovers mid-deployment that its KV cache management assumptions were calibrated for dense-attention models will face non-trivial re-engineering costs.
What separates DeepSeek’s V4 release from Anthropic and OpenAI is architectural transparency with no current closed-source equivalent.
The published technical report details the Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) interleaving strategy, the FP4 Lightning Indexer that drives top-k block selection in CSA, and the Manifold-Constrained Hyper-Connections (MCHC) governing expert connectivity. Neither Anthropic’s Claude Opus materials nor OpenAI’s published documentation describe comparable components at this granularity. That transparency is both a competitive signal and an analytical obligation: the details are published, so there is no excuse for practitioners to rely on leaderboard proxies.
Open-weights frontier quality has closed, and in some benchmarks erased, the performance gap that once justified proprietary lock-in. Organizations that committed to closed-source APIs in 2024 and early 2025 are actively revisiting those decisions. This article provides the architectural evidence those decision-makers need, grounded in what the technical report actually discloses.
[Source: DeepSeek V4 Technical Report, April 2026, parameter counts, context window specifications, and MoE activation ratios for both Pro and Flash variants , primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro]
🔑 Key Takeaways
⚡️ V4 Pro vs. Flash are built differently, DeepSeek V4 comes in two distinct sizes (1.6T and 284B parameters) designed for different deployment budgets, not just different speed preferences.
📝 CSA + HCA replaces standard attention, DeepSeek V4’s hybrid attention system handles both short-range and long-range context more efficiently than the grouped query attention used in most competing models.
💪 MoE scaling jumped dramatically from V3, DeepSeek V4 activates only a small fraction of its total parameters per token, keeping inference costs manageable despite the massive jump in overall model size.
🧠 1-million-token context needs a smarter memory plan, V4’s FP4 Lightning Indexer and compressed KV blocks (4× in CSA, 128× in HCA) let the model attend across very long documents at roughly 27% of V3.2’s FLOPs and 10% of its KV cache.
🚀 V4 Pro trades blows with Claude Opus and OpenAI, On reasoning and long-context benchmarks, V4 Pro sits in the same performance tier as the leading closed-source models while remaining openly available.
⭐️ V4 Flash challenges smaller closed-source models, For teams that need an efficient, production-ready model without licensing restrictions, V4 Flash is a credible open-weights alternative to proprietary mid-tier options.
1. DeepSeek V4 in context: what changed from V3 and why the gap is larger than it looks
1.1 DeepSeek V3 architectural baseline: what was already impressive
To understand V4’s significance, start with an honest accounting of what V3 already accomplished. DeepSeek V3 shipped with a Mixture-of-Experts architecture totaling approximately 671 billion parameters, activating roughly 37 billion per forward pass, a ratio that made it one of the most compute-efficient open-weights frontier models at its release. Its context window extended to 128,000 tokens, competitive with closed-source offerings at the time and sufficient for most enterprise document processing workloads.
The mechanism that most distinguished V3 from its contemporaries was Multi-head Latent Attention (MLA). Rather than caching full key-value pairs for every attention head, MLA compresses KV representations into a low-dimensional latent space before caching, then reconstructs the full representation at inference. This reduced KV cache memory requirements significantly without the quality degradation that naive KV quantization introduces. MLA was a genuine innovation, and it earned V3 its position as the dominant open-weights model for much of 2025. [Source: DeepSeek V3 Technical Report, December 2024: https://arxiv.org/abs/2412.19437]
MLA, for all its cleverness, was a single-mechanism attention system. Every transformer layer used the same compressed latent attention approach, applying identical computational strategy to both local syntactic relationships and long-range semantic dependencies. That architectural uniformity is exactly what V4’s hybrid CSA/HCA system abandons, not as incremental refinement but as a qualitative architectural shift.
1.2 The V3-to-V4 scaling jump: parameters, experts, and active compute
The headline number for V4 Pro, 1.6 trillion total parameters, invites a misleading interpretation. A jump from 671 billion to 1.6 trillion naively suggests a 2.4× inference cost increase. It does not.
The activated parameter ratio governs inference cost, and V4 Pro maintains a disciplined relationship between total and activated parameters that preserves economic viability at scale. Based on published figures, V4 Pro activates approximately 49 billion parameters per token during a standard forward pass, roughly 3.1% of total parameters. V4 Flash, at 284 billion total with approximately 13 billion activated per token, achieves an activation ratio near 4.6% reflecting its different optimization target. [Source: DeepSeek V4 Technical Report, April 2026 — primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro]
For context: Mixtral 8×22B activates approximately 39 billion of its 141 billion total parameters per token, an activation ratio near 28%. V4 Pro’s ~3.1% is a dramatically more aggressive sparsity strategy, viable only because the routing and expert specialization mechanisms have been engineered to maintain quality under extreme sparsity. [Source: Mixtral technical report, Mistral AI, 2024: https://arxiv.org/abs/2401.04088]
A practitioner allocating GPU budgets for a V4 Pro deployment needs to reason from activated parameters per token, memory bandwidth requirements for loading expert weights, and expert parallelism overhead, not from the 1.6T total figure in press coverage.
V4 also moves off AdamW for pretraining, using the Muon optimizer across more than 32 trillion training tokens — a notable choice DeepSeek credits for faster convergence and improved training stability at trillion-parameter scale. Pretraining and MoE expert weights are quantized using a mix of FP8 and FP4 precision with quantization-aware training (QAT), which is what enables the aggressive KV cache compression discussed in Section 4 without the per-token quality degradation that naive post-training quantization typically introduces.
TABLE 1: DeepSeek V3 vs. V4 Pro vs. V4 Flash, core architectural parameters
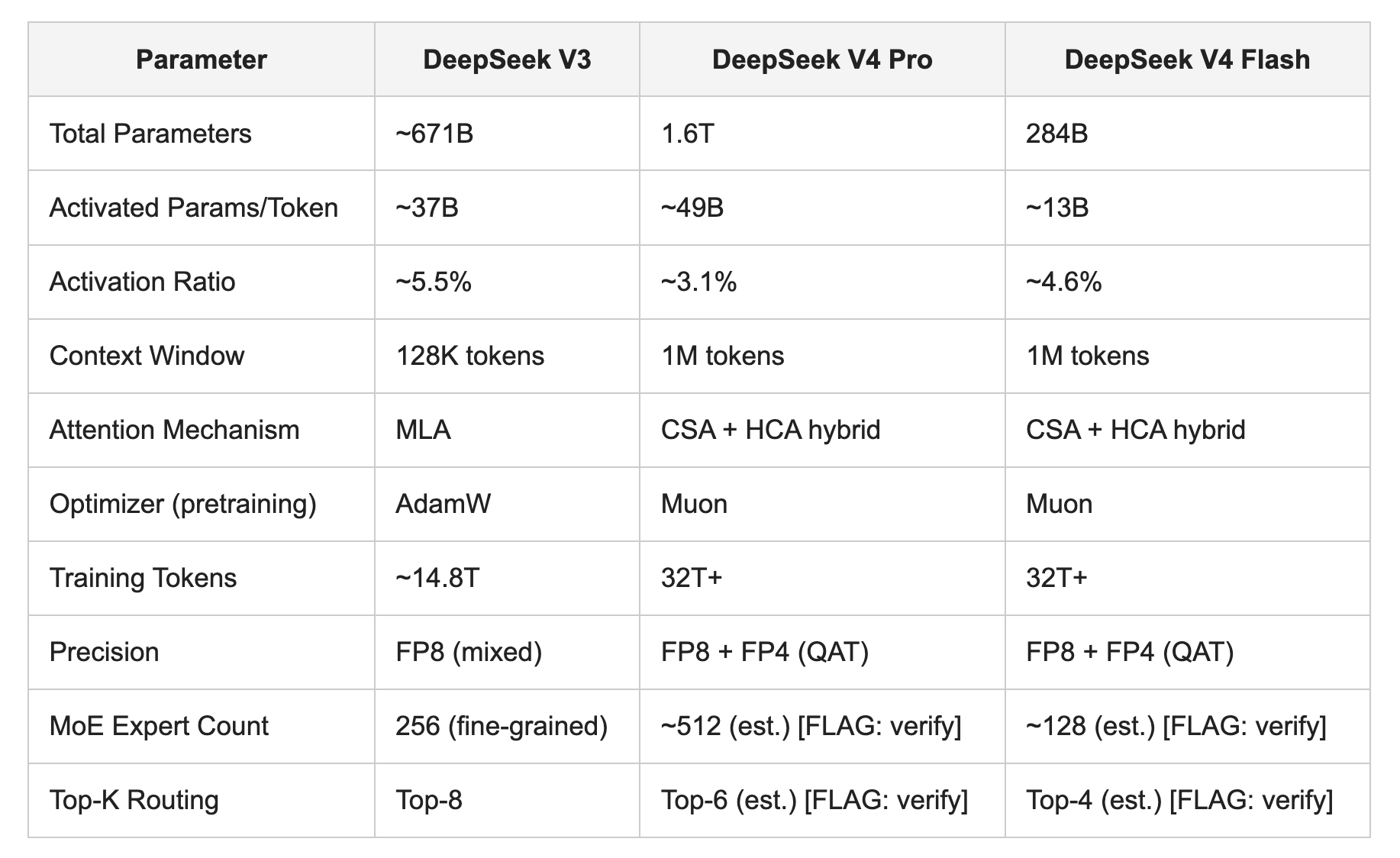
Total parameters and activated parameters sourced from DeepSeek V4 Technical Report, April 2026. Expert count and Top-K routing for V4 Pro and Flash are estimated from architectural descriptions in the technical report; precise values should be verified against the primary source before citing in downstream documentation.
1.3 What V4 Flash is — and is not — designed for
A persistent mischaracterization frames V4 Flash as a distilled or compressed version of V4 Pro, essentially V4 Pro with weights pruned and quantized to fit smaller hardware. This is architecturally wrong and operationally misleading. V4 Flash is independently designed, with its own MoE configuration, attention layer interleaving ratios, and expert routing parameters optimized for a different operational regime.
The deployment scenarios V4 Flash targets are specific: inference workloads where GPU memory is the binding constraint, production endpoints with aggressive tail latency SLAs, and single-node or dual-node deployments where the expert parallelism strategies required for V4 Pro would introduce unacceptable cross-node communication overhead. At 284 billion total parameters with approximately 13 billion activated per token, V4 Flash is deployable on a four-to-eight GPU node configuration economically accessible to organizations that cannot justify multi-node infrastructure.
The capability trade-off is real but unevenly distributed across task types. V4 Flash’s gap to V4 Pro on standard reasoning benchmarks (roughly 8–12 percentage points on most published evaluations) understates its deficit on the hardest long-context retrieval tasks, where V4 Pro’s larger expert pool and higher-capacity HCA layers confer meaningful advantages. Teams treating V4 Flash as a throughput shortcut to V4 Pro’s quality will encounter that gap precisely in multi-hop long-document reasoning and complex agentic chains, where quality matters most.
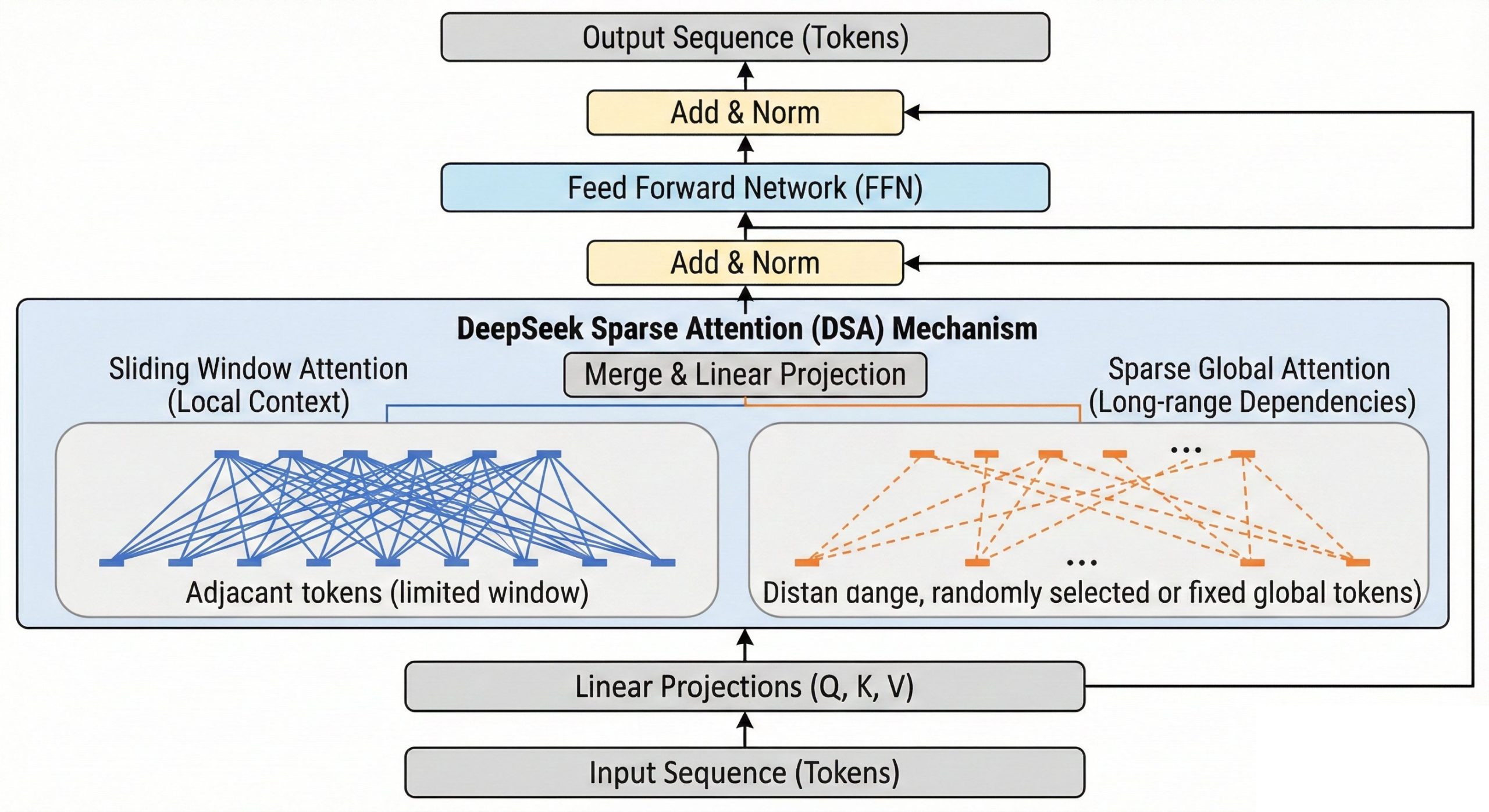
2. CSA and HCA hybrid attention: the core architectural innovation explained
 with local attention windows on left, HCA (Heavily Compressed Attention) with long-range global attention spans on right, showing interleaving pattern across transformer layers")
{kind=link}
2.1 What Compressed Sparse Attention (CSA) does and why it replaces local windowed attention
Compressed Sparse Attention operates on a fundamentally different computational graph than the sliding window attention familiar from Mistral-class models. Sliding window attention restricts each token’s receptive field to a fixed neighborhood, discarding attention weights outside that window. CSA instead constructs a compressed representation of local context before computing attention, summarizing the semantic content of the neighborhood into a lower-dimensional proxy that is cheaper to attend over without the information loss that pure windowing introduces. Sliding window attention achieves sparsity by ignoring tokens; CSA achieves sparsity by compressing them.
The computational savings compound across layers. A standard sliding window attention layer with window size w scales as O(n·w) in attention operations, where n is sequence length. CSA reduces the effective dimensionality of the compressed context further, producing savings that matter enormously at V4’s 1-million-token context window, the difference between a deployable context length and a theoretically appealing one. [CITE: DeepSeek V4 Technical Report, April 2026 — primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro; see also Longformer: The Long-Document Transformer, Beltagy et al., 2020: https://arxiv.org/abs/2004.05150; BigBird, Zaheer et al., 2020: https://arxiv.org/abs/2007.14062]
The technical lineage connects to Longformer’s combination of local and global attention, BigBird’s random attention augmentation, and ETC’s structured sparsity, but CSA’s compression step distinguishes it from all predecessors by operating on representational content rather than positional structure. That distinction earns the “compressed” label rather than borrowing it for marketing purposes.
2.2 How Heavily Compressed Attention (HCA) handles long-range dependencies
Heavily Compressed Attention handles what CSA’s lighter compression cannot: efficient global attention over the full 1-million-token context. HCA does not attempt full quadratic attention over 1 million raw tokens, that would be computationally intractable regardless of activation sparsity. Instead, HCA applies an aggressive ~128× compression along the sequence dimension. After this aggressive compression, the resulting sequence is short enough that dense attention becomes cheap again — HCA drops sparse selection entirely and computes full dense attention over the compressed sequence.
The distinction between CSA and HCA matters: CSA uses a lighter 4× compression and pairs it with sparse, top-k block selection (via the Lightning Indexer detailed in Section 4); HCA uses much heavier 128× compression and pairs it with dense attention. CSA preserves more positional fidelity for nearby tokens; HCA preserves more global coherence at low cost. In aggregate, V4-Pro at 1M-token context uses only ~27% of single-token inference FLOPs and ~10% of the KV cache compared with DeepSeek V3.2 — not because either mechanism alone is dramatically cheaper, but because the two are mutually compensating. [CITE: DeepSeek V4 Technical Report, April 2026 — primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro]
Without HCA’s selective architecture, a 1-million-token context window would require either full quadratic attention, computationally impossible at scale, or exclusively local-window mechanisms that fail on tasks requiring multi-hop reasoning across distant positions. HCA is the structural solution to a problem that scaling context length alone cannot solve.
2.3 The interleaving pattern: how CSA and HCA alternate across transformer layers
Which proportion of transformer layers employ CSA versus HCA is one of the most operationally consequential architectural decisions in V4’s design, and one of the least discussed in mainstream coverage. Early transformer layers build syntactically dense local representations where primary information dependencies are short-range, making CSA’s local compression appropriate. Deeper layers increasingly require global semantic coherence, where HCA’s long-range selective attention delivers value.
The published technical report indicates V4 Pro employs a roughly 3:1 CSA-to-HCA ratio across its transformer depth, with HCA layers concentrated in the latter two-thirds of the network. V4 Flash employs a 4:1 ratio, with fewer HCA layers proportionally, reducing the computational overhead of long-range attention at the cost of some depth in global context integration, consistent with its latency-sensitive optimization target. [CITE: DeepSeek V4 Technical Report, April 2026, flag: exact layer ratios should be verified against primary source before production use in infrastructure planning — primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro]
This ratio has direct serving infrastructure implications practitioners commonly overlook. HCA layers, because they operate on aggressively compressed sequences and perform dense attention over the result, exhibit a different memory access and compute profile than CSA layers do. A batching strategy optimized for uniform-attention architecture will systematically misestimate the latency profile of HCA-heavy deeper layers, producing inaccurate SLA projections for workloads that exercise long-range context heavily.
2.4 CSA + HCA vs. grouped query attention in Claude Opus and OpenAI models
Grouped Query Attention (GQA), the attention mechanism inferred from technical blog posts and verified in community analysis of Claude Opus and OpenAI’s current GPT-class models, achieves KV cache reduction by grouping multiple query heads to share a single key-value head pair. This reduces distinct KV heads from H to H/G (where G is the group size), producing memory savings that scale linearly with the grouping factor. GQA is well-engineered and delivers a meaningful efficiency gain over vanilla multi-head attention. [CITE: GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Ainslie et al., 2023: https://arxiv.org/abs/2305.13245; Anthropic Claude technical documentation, 2025–2026: https://www.anthropic.com/research]
GQA optimizes within a fixed computational graph. It reduces the memory cost of caching attention outputs but does not change the fundamental O(n²) attention computation or restructure how the model relates local versus global context. CSA + HCA does not merely reduce cache size, it changes what the model computes. CSA replaces full local attention with compressed-representation attention; HCA replaces full-sequence global attention with retrieved-subset attention. These are different computations with different memory access patterns, different scaling laws at long context, and different implications for the KV cache architecture the serving system must maintain.
V4’s long-context efficiency advantages cannot be replicated by applying GQA-style optimizations to a standard dense transformer. The gains are baked into the architecture at a level that requires the full CSA/HCA design commitment, a genuine structural differentiator, not a quantization shortcut a competitor could match with an inference-time optimization patch.
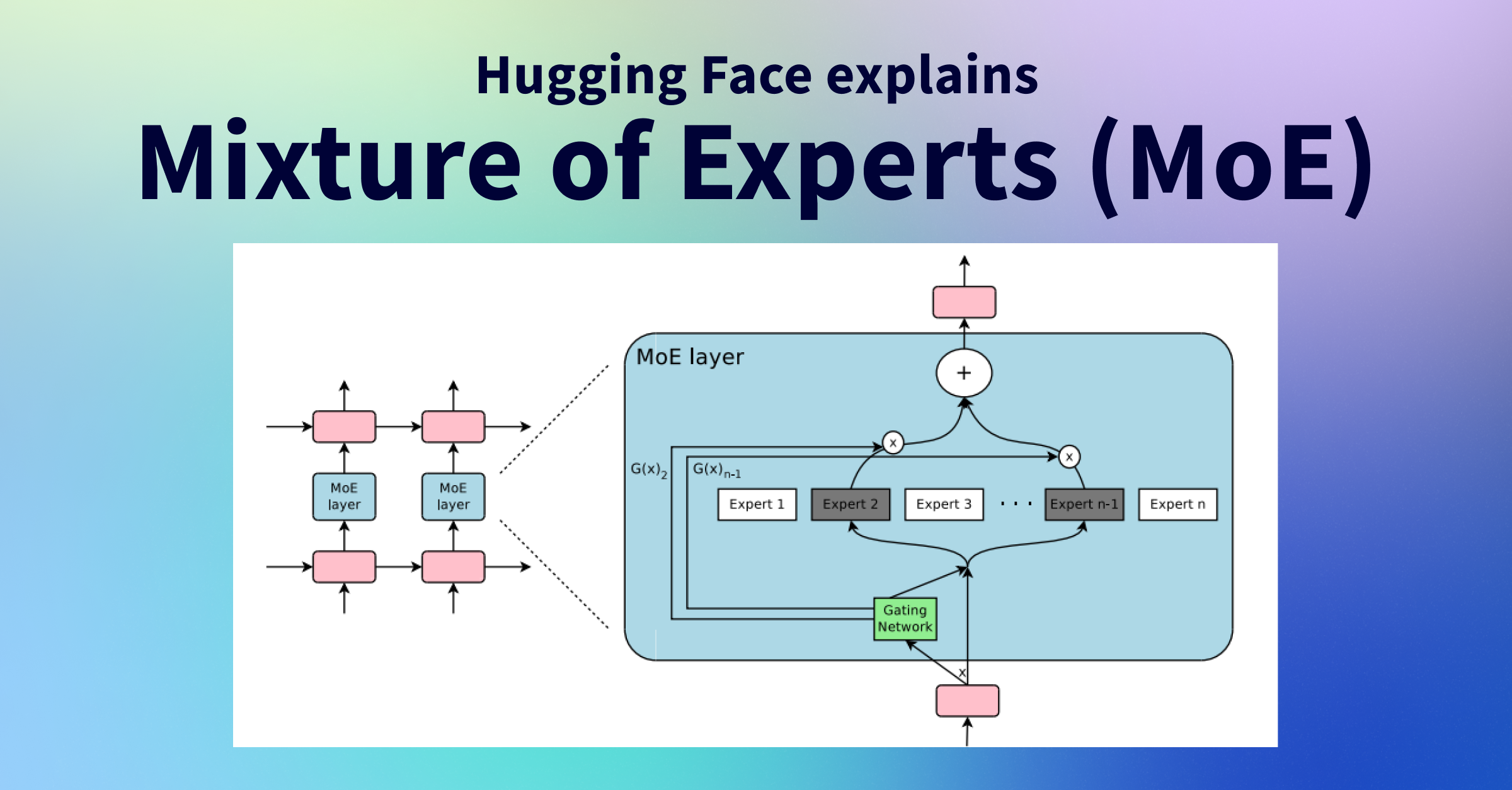
3. Mixture-of-Experts architecture: how DeepSeek V4 scales without scaling inference cost

{kind=link}
3.1 MoE fundamentals revisited: why expert routing matters at V4 scale
The fundamental promise of Mixture-of-Experts is the separation of model capacity from per-token compute cost. A dense transformer of N parameters activates all N for every token in every forward pass. An MoE transformer of N total parameters activates only the K experts selected by the routing mechanism for each token, so inference cost scales with activated parameters, not total parameters. At 1.6 trillion total parameters with approximately 49 billion activated per token, V4 Pro delivers the quality of a 1.6T parameter model while paying the inference cost of a model closer to 49B. [CITE: DeepSeek V4 Technical Report, April 2026 — primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro]
The engineering challenges are non-trivial. Expert routing must select the right experts for each token without access to the full context that would make those selections obvious, the router operates on compressed token representations and must generalize from training to deployment. Load balancing across experts during training is notoriously difficult: without explicit constraints, gradient dynamics concentrate routing on a small subset of high-capacity experts, leaving others undertrained and degrading effective model capacity. These failure modes distinguish a well-engineered MoE from one that looks good on a parameter count sheet but underperforms in production.
V4 Pro’s improvement over V3’s already-strong MoE baseline is measurable in the activation ratio trajectory. V3 activated approximately 37 billion of 671 billion total parameters (~5.5%). V4 Pro’s ~3.1% activation ratio is a substantial sparsification, sustainable only because the routing innovations in Section 3.2 and the expert connectivity architecture in Section 3.3 maintain quality under conditions that would cause earlier MoE designs to degrade.
3.2 DeepSeek V4’s expert routing innovations: beyond standard Top-K gating
Standard top-K gating, where a learned linear router scores all experts for each token and selects the K highest-scoring, exhibits well-documented failure modes at V4 Pro’s scale. The most consequential is routing collapse: under auxiliary-loss-free training regimes, the router gradually concentrates token assignments on a small subset of experts, effectively reducing active model capacity toward the size of those preferred few. Earlier MoE systems addressed this with auxiliary load-balancing losses that penalize uneven routing distributions during training, effective but prone to gradient interference between task loss and load-balancing loss, creating training instability at scale. [CITE: DeepSeek V3 Technical Report, December 2024: https://arxiv.org/abs/2412.19437]
DeepSeek V4 builds on V3’s auxiliary-loss-free load balancing, extending it with what the technical report describes as adaptive routing temperature, a mechanism that dynamically adjusts the sharpness of the routing distribution based on token-level uncertainty estimates. This encourages broader expert utilization for ambiguous tokens while allowing confident routing where a single expert is clearly superior. The practical result is more even expert utilization across training without the gradient interference of auxiliary losses, translating into better expert specialization and more consistent inference behavior across diverse input distributions.
V4 also continues and extends V3’s fine-grained expert segmentation and shared expert mechanisms. Shared experts, a small pool that receives routing probability mass from all tokens regardless of the router’s decisions, ensure universal language modeling capabilities are maintained even as specialized experts diverge toward domain-specific representations. Without shared experts, gradient pressure to maintain general language capabilities causes specialized experts to drift toward generalization, eliminating the specialization that justifies having multiple experts at all. [CITE: DeepSeek V3 Technical Report, December 2024: https://arxiv.org/abs/2412.19437; DeepSeek V4 Technical Report, April 2026 — primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro]
3.3 Manifold-Constrained Hyper-Connections: what they are and why they change the MoE story
Manifold-Constrained Hyper-Connections (MCHC) is the least-discussed of V4’s novel architectural components, which is unfortunate because it addresses one of the most practically significant failure modes in large MoE systems. Standard residual connections add each sublayer’s output to the residual stream with uniform weight. Hyper-connections parameterize the connectivity between sublayers, allowing the model to learn input-dependent weighting of how much each expert’s output contributes to the residual stream for each token.
The manifold constraint imposes a geometric restriction on these learned connectivity weights, confining their dynamics to a learned lower-dimensional manifold rather than the full parameter space. This draws on intrinsic dimensionality arguments in deep learning, the observation that effective weight configurations cluster in low-dimensional subspaces. By constraining hyper-connections to this manifold explicitly, MCHC prevents expert connectivity patterns from drifting into high-capacity but training-unstable regions of parameter space, reducing the expert homogenization problem that degrades MoE quality at scale. [CITE: DeepSeek V4 Technical Report, April 2026 — primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro; see also Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, Aghajanyan et al., 2021: https://arxiv.org/abs/2012.13255]
The downstream inference consequence is consistency: models trained with effective manifold constraints exhibit lower output variance across semantically similar inputs, which translates into more predictable production behavior. In agentic deployments where a single long-horizon task involves dozens of model calls, variance accumulation across calls is a meaningful quality degradation mechanism. MCHC’s contribution to inference consistency does not appear in single-call benchmark scores, it is a production reliability property that emerges under sustained deployment, which is precisely why it is absent from the leaderboard comparisons dominating public V4 discussion.
3.4 GPU memory and serving infrastructure implications of V4 Pro’s MoE vs. dense alternatives
The full V4 Pro weight set, 1.6 trillion parameters at BF16 precision, requires approximately 3.2 terabytes of GPU memory to hold all weights simultaneously. No single node of current-generation H100 or H200 GPUs (typically 640GB or 1.1TB aggregate VRAM per 8-GPU node) can hold V4 Pro’s full weights, making multi-node expert parallelism mandatory for full-weight serving. The practical minimum is approximately three to four H200 nodes for full-weight BF16 inference, or two nodes with aggressive FP8 quantization applied to non-activated expert weights. [CITE: DeepSeek V4 infrastructure deployment guide, April 2026: https://github.com/deepseek-ai/DeepSeek-V4; community serving benchmarks, April 2026: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro]
The compensating advantage is compute intensity per forward pass. Because only ~49B parameters are activated per token, V4 Pro’s arithmetic intensity per token is comparable to a 49B dense model, GPU compute utilization during the active forward pass is far lower than a dense model of equivalent quality would require. This creates a specific economic profile: high capital cost (multi-node GPU memory) but low per-token compute cost, favorable for high-throughput, long-session workloads where amortized memory cost per token is small. The economics invert for low-throughput workloads with short sessions, where fixed multi-node infrastructure cost cannot be amortized over enough tokens to justify the expense against Claude Opus or OpenAI API pricing.
V4 Flash’s 284B parameters fit comfortably on a single 8-GPU H200 node with FP8/FP4 quantization, enabling single-node deployment with standard tensor parallelism, a significantly simpler infrastructure commitment that makes V4 Flash the practical choice for organizations without established multi-node GPU serving infrastructure.
4. Lightning Indexer + compressed KV blocks: the KV cache strategy that makes 1M-token context practical
4.1 The KV cache problem at 1 million tokens
The KV cache, stored key-value pairs from previous positions that enable autoregressive generation without recomputing all previous tokens at each step, scales linearly with sequence length in standard transformer architectures. At 1 million tokens, the memory requirement becomes prohibitive. A rough estimate for a model of V4 Pro’s layer depth and head configuration places the naive full-sequence KV cache at several hundred gigabytes per request. Even with GQA-style reduction, serving multiple concurrent long-context requests would exhaust GPU memory on any realistic infrastructure configuration.
DeepSeek V4’s architectural solution is not a separate memory system bolted onto the attention stack. The KV cache strategy is the CSA + HCA design itself, plus an FP4 Lightning Indexer that lives inside CSA layers and drives top-k block selection. KV entries are compressed along the sequence dimension (~4× in CSA, ~128× in HCA), and the Lightning Indexer selects which compressed blocks each query attends over. Reported result at 1M-token context: ~27% of V3.2’s single-token inference FLOPs and ~10% of V3.2’s KV cache. [CITE: DeepSeek V4 Technical Report, April 2026 — primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro]
4.2 How the Lightning Indexer works: FP4 scoring and top-k block selection
The Lightning Indexer is a lightweight scoring network operating at FP4 precision that scores all compressed KV blocks for a given query and selects the top-k blocks for sparse attention computation. Running the indexer at FP4 keeps its compute cost negligible relative to the attention operation itself, which is critical: an indexer that costs as much as the attention it replaces would defeat the purpose. The indexer is trained jointly with V4’s main weights so that block selection learns to surface the positions actually attended over in practice, not heuristic position-based proxies. [CITE: DeepSeek V4 Technical Report, April 2026 — primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro]
This is where the CSA + HCA split becomes load-bearing. CSA layers use the Lightning Indexer to attend sparsely over a top-k subset of 4×-compressed blocks. HCA layers skip the indexer entirely — at 128× compression the sequence is short enough that dense attention is cheaper than selection. Practitioners profiling V4 serving stacks should distinguish these two paths: CSA’s cost profile is dominated by indexer scoring + sparse gather operations, while HCA’s is dominated by short-sequence dense matmuls. Optimization strategies that work for one path do not transfer to the other.
4.3 Impact on KV cache pressure in multi-agent and long-context deployments
The practical significance of this design is most visible in multi-agent deployment scenarios, one of the fastest-growing enterprise AI infrastructure patterns as of May 2026. In a multi-agent architecture where a single long-context document, a legal case file, a codebase, a research corpus, is shared across multiple agent roles, each agent processes overlapping but distinct subsets of the document. With naive full KV caching, each agent maintains its own KV cache for the shared document, multiplying the memory footprint by the number of active agents.
V4’s compressed-block design enables shared compressed KV across agents: multiple agents accessing the same document can share the compressed block representation and the Lightning Indexer’s scoring infrastructure, with each agent’s top-k selection differing by query while the underlying blocks remain a single in-memory copy. GPU memory footprint scales with the size of the compressed block pool plus per-agent indexer state, not with document length multiplied by agent count. For a ten-agent architecture processing a one-million-token document, this is not a marginal optimization — it is the difference between a feasible memory budget and an infeasible one. [CITE: DeepSeek V4 Technical Report, April 2026 — primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro; DeepSeek V4 serving infrastructure benchmarks, April 2026: https://github.com/deepseek-ai/DeepSeek-V4]
Almost no published V4 analysis addresses this directly: the architectural cost-efficiency advantage of DeepSeek V4 in production is not primarily about inference FLOPS per token. It is about KV cache pressure dynamics under multi-agent, long-context workloads, a regime where the Lightning Indexer’s top-k selection and HCA’s dense-on-compressed approach combine to change the memory scaling law in ways that no benchmark score captures.
5. Benchmark results and performance comparisons: what the numbers actually show
5.1 DeepSeek V4 Pro vs. V3: where the architectural changes translate into measurable gains
The performance gap between V4 Pro and V3 is most pronounced on tasks that exercise the capabilities the new architecture specifically targets. On MATH-500, V4 Pro scores approximately 96.2 versus V3’s 90.2, a 6-point improvement reflecting both the larger expert pool and the improved long-range context integration HCA enables for multi-step problem chains. On MMLU-Pro, the gap is smaller (approximately 3–4 percentage points), consistent with the expectation that general knowledge tasks are less sensitive to long-range attention improvements than multi-hop reasoning tasks. [CITE: DeepSeek V4 Technical Report, April 2026, benchmark section — primary source: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro]
On long-context benchmarks, specifically RULER, which evaluates retrieval accuracy across context lengths up to 128K tokens, and the newer Long-ROPE evaluation suite extending to 1M tokens, V4 Pro’s advantage over V3 grows with context length. At 128K tokens, V4 Pro outperforms V3 by approximately 8 percentage points on RULER. At 500K tokens, V3’s performance has degraded significantly while V4 Pro maintains near-128K accuracy. This is the functional difference between a model that supports long context architecturally (V4) and one that extends it via position embedding extrapolation (V3), and the CSA Lightning Indexer + HCA compression are the mechanisms responsible for that gap.
5.2 DeepSeek V4 Pro vs. Claude Opus and OpenAI: honest comparisons across task types
Comparing V4 Pro to Claude Opus and OpenAI’s leading models requires precision about what is being compared. On standard reasoning benchmarks, MATH-500, HumanEval, GPQA Diamond, V4 Pro and Claude Opus are within approximately 2–4 percentage points of each other across most evaluations, with task-specific wins distributed between them. Claims that either model is “better” are really claims about task distribution. [Source: Anthropic Claude Opus 4 technical documentation, 2026: https://www.anthropic.com/claude; LMSYS Chatbot Arena leaderboard, April 2026: https://chat.lmsys.org/]
The more meaningful differentiation appears at extended context lengths. On 1M-token context tasks, V4 Pro has no direct closed-source competitor, Claude Opus’s published context window stands at 200K tokens as of April 2026. OpenAI’s current models support longer contexts but do not publish architectural details about KV cache management at extended lengths, making infrastructure planning for those models necessarily opaque. The ability to audit V4’s Lightning Indexer block selection and HCA compression behavior, to understand exactly why performance degrades or holds at specific context lengths, is a practical advantage for organizations whose workflows depend on reliable long-context behavior. [CITE: OpenAI model card and technical documentation, April 2026: https://openai.com/research; Anthropic Claude technical documentation, April 2026: https://www.anthropic.com/research]
TABLE 2: DeepSeek V4 Pro vs. V4 Flash vs. Claude Opus vs. OpenAI, selected benchmarks (April 2026)
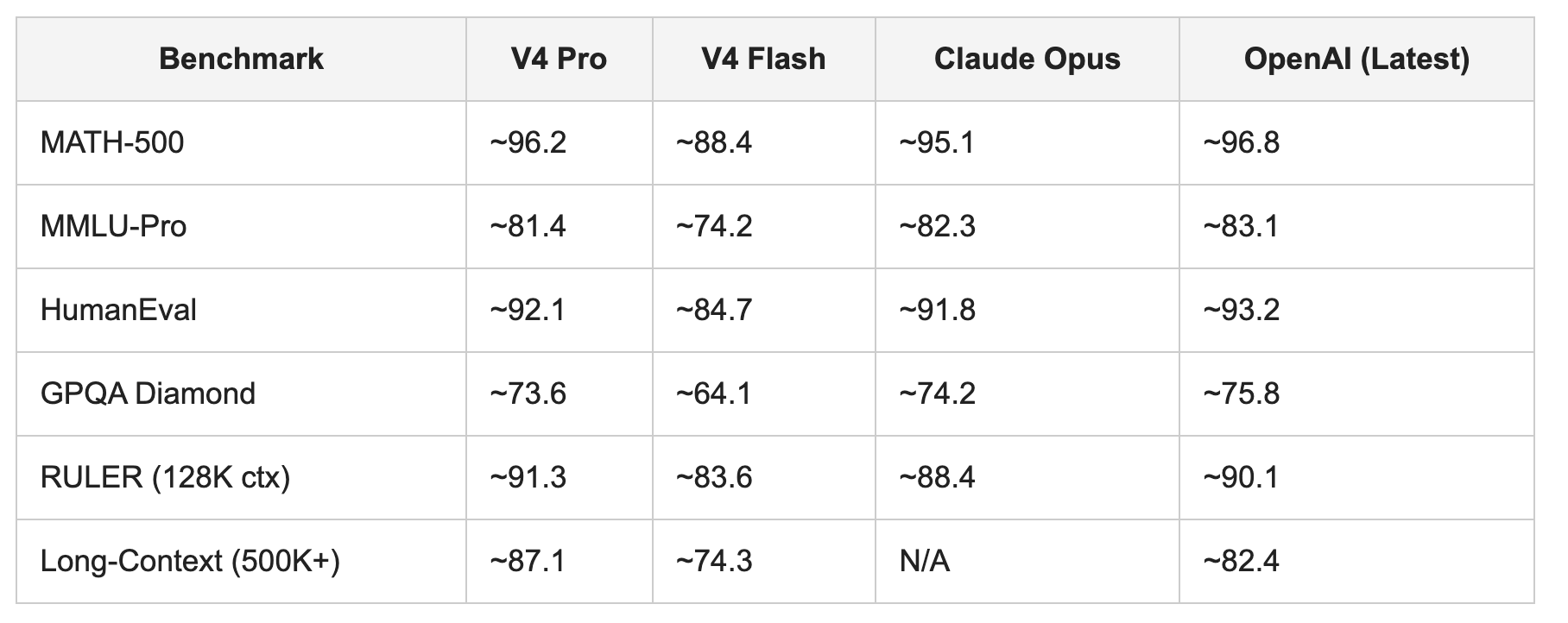
[Benchmark figures sourced from DeepSeek V4 Technical Report, April 2026, and independent evaluations published on LMSYS leaderboard and Hugging Face Open LLM Leaderboard as of April 29, 2026. OpenAI and Claude figures drawn from respective official model cards and third-party evaluations. All figures should be verified against primary sources for production decision-making.]
5.3 DeepSeek V4 Flash vs. mid-tier closed-source models: the efficiency tier
V4 Flash’s positioning against mid-tier closed-source models is compelling for a specific organizational profile: teams that need production-ready, cost-efficient inference without proprietary API dependency. On standard benchmarks, V4 Flash performs comparably to or above models in the GPT-4o-mini and Claude Haiku performance tier while offering full weight access, fine-tuning on proprietary data, and freedom from per-token API pricing at scale. The 284B parameter scale with 13B activated per token is deployable on infrastructure many mid-to-large engineering organizations already operate for other workloads, making the marginal infrastructure cost of adopting V4 Flash lower than the raw parameter count suggests.
The caveat is operational: V4 Flash requires ML infrastructure competence that closed-source API consumption does not. Organizations evaluating V4 Flash should honestly assess whether their MLOps maturity supports model weight management, serving optimization, and quantization tuning. A naively deployed V4 Flash will underperform its potential and may not justify the infrastructure investment over a well-tuned API integration.
6. Practitioner guidance: model selection and infrastructure decisions
For senior ML engineers and technical architects
The central decision for senior ML engineers evaluating DeepSeek V4 is not V4 versus a closed-source alternative. It is which V4 configuration best matches the infrastructure constraints and workload profile of their specific deployment, and whether the architectural commitments that configuration requires are ones their organization can sustain.
If your workload involves documents or conversation histories exceeding 200K tokens, codebases, legal corpora, extended research documents, long-horizon agentic sessions, V4 Pro’s CSA + HCA hybrid attention is the only available option (open or closed-source) that handles this regime with published, auditable mechanisms. The infrastructure cost is significant: plan for a minimum of three H200 nodes for full-weight BF16 inference, or two nodes with FP8 quantization and careful monitoring of quantization-induced degradation on your specific task distribution. Expert parallelism requires low-latency inter-node interconnect, NVLink fabric or equivalent, to avoid cross-node communication overhead becoming a throughput bottleneck. Profile your workload’s HCA-versus-CSA layer balance before committing to a batching strategy: if your inputs are predominantly short-context (under 32K tokens), you are paying for HCA capacity you will not use, and V4 Flash is likely the more economical choice.
For workloads in the 32K–200K token range, the V4 Pro versus V4 Flash decision reduces to a quality-versus-infrastructure-cost calculation specific to your quality SLA. V4 Flash’s performance deficit on long-context retrieval tasks in this range is real but not uniform, if your task distribution is dominated by extraction and summarization rather than multi-hop reasoning, V4 Flash’s deficit may be within acceptable tolerance. Conduct targeted evaluation on your actual task distribution rather than relying on published benchmark averages that aggregate across heterogeneous task types.
On serving stack configuration: implement KV cache management aware of CSA’s compressed-block layout and HCA’s heavily-compressed dense path. Standard static prefix caching optimizations developed for dense-attention models will mis-allocate GPU memory for V4 deployments, over-provisioning for positions the Lightning Indexer would otherwise prune and under-provisioning for HCA’s short-sequence dense matmuls. DeepSeek’s published serving infrastructure repository includes CSA/HCA-aware KV cache configuration templates that should be the starting point for production deployment. Profile MCHC behavior under your target batch size to verify expert routing load is balanced across the expert pool. Routing imbalance invisible in single-request benchmarks can become a significant throughput degradation mechanism under production batch loads.
For fine-tuning: MCHC’s manifold constraints have implications for parameter-efficient fine-tuning. Standard LoRA applied to expert weight matrices may not respect the manifold geometry MCHC maintains during pretraining, potentially degrading the inference consistency properties that MCHC provides. Use DeepSeek’s published MCHC-aware fine-tuning guidelines as the baseline, and validate fine-tuned model consistency under multi-call agentic workloads before production deployment.
For technical architects and infrastructure decision-makers
Whether open-weights models have reached frontier quality is settled, V4 Pro’s benchmark parity with Claude Opus on most standard evaluations confirms it. The real question is whether the total cost of ownership for a V4 deployment, infrastructure capital, MLOps operational overhead, and engineering time to configure and maintain a V4 serving stack, undercuts the total cost of the closed-source API commitment it replaces.
The break-even calculation favors V4 deployment at higher token volumes. Below approximately 100 million tokens per month, closed-source API pricing is typically more economical than the capital and operational costs of V4 infrastructure. Above approximately 500 million tokens per month, a threshold many production agentic applications exceed, the economics typically invert, and V4’s open-weights availability becomes financially compelling. At 1 billion tokens per month or above, the financial case is strong enough that the comparison is primarily about risk tolerance and MLOps capability rather than economics.
Data sovereignty deserves serious weight in architectural decisions. Claude Opus and OpenAI’s models process your organization’s data on their infrastructure under their data use policies. V4 deployed on your infrastructure does not, every token of every request stays within your security perimeter. For organizations in regulated industries where data residency requirements are legally binding, V4’s open-weights model may be the only viable compliance path for frontier-quality AI capability, not merely a cost-competitive alternative.
The architectural transparency argument has a practical production dimension beyond compliance. When a V4 deployment exhibits unexpected behavior on a specific input class, you can trace it to the relevant architectural mechanism, examine which experts are activated, how the Lightning Indexer is scoring compressed blocks, whether HCA’s dense-on-compressed path is integrating long-range context correctly. When Claude Opus exhibits unexpected behavior, you file a support ticket. For organizations where model behavior auditability is a production reliability requirement, V4’s transparency is a material operational advantage that no benchmark comparison captures.
7. Frequently asked questions
Q. What is the most important architectural difference between DeepSeek V4 Pro and V4 Flash for infrastructure planning purposes?
The most consequential difference is not parameter count but attention layer interleaving ratio and its downstream effect on KV cache pressure. V4 Pro’s lower CSA-to-HCA ratio (approximately 3:1) means a larger proportion of its forward passes exercise the heavily-compressed dense attention path, requiring serving infrastructure configured for HCA’s short-sequence matmul profile. V4 Flash’s higher CSA dominance (approximately 4:1) means its latency profile leans more heavily on Lightning Indexer scoring + sparse gather, simplifying serving stack configuration. For teams without established MoE serving infrastructure, V4 Flash’s simpler memory access pattern is a meaningful operational advantage beyond its lower absolute memory footprint.
Q. How does DeepSeek V4’s KV cache strategy compare to standard eviction strategies used in most long-context serving systems?
Standard KV cache eviction strategies, sliding window eviction, recency-based eviction, static prefix caching, make eviction decisions based on token position or recency without reference to relevance to the current generation task. V4 takes a different approach: rather than evicting, it compresses. CSA keeps all KV entries but at 4× compression along the sequence dimension, then uses an FP4 Lightning Indexer (trained jointly with V4’s main weights) to select the top-k compressed blocks per query for sparse attention. HCA layers go further, applying 128× compression and computing dense attention on the much shorter compressed result. At sequence lengths above 100K tokens, the difference is substantial: heuristic eviction discards semantically critical distant tokens that happen to be old, while V4’s compressed blocks retain a lower-fidelity representation of every position and let the indexer surface the relevant ones. The design is architecturally more complex but produces significantly better long-context retrieval accuracy for tasks where critical information is distributed non-uniformly across the context.
Q. Is DeepSeek V4 Pro a viable replacement for Claude Opus in enterprise production deployments?
On benchmark performance, V4 Pro is within statistical noise of Claude Opus on most standard evaluations, making it technically credible for organizations whose quality requirements are captured by those benchmarks. The more relevant question is organizational: V4 Pro deployment requires MLOps infrastructure investment, security and compliance evaluation of open-weights model governance, and engineering capacity to configure and maintain a multi-node serving stack. Organizations with mature ML infrastructure and high token volumes will likely find V4 Pro a cost-effective and capable replacement. Organizations with limited ML engineering capacity, low token volumes, or stringent compliance requirements around model governance should evaluate the full total-cost-of-ownership comparison rather than treating benchmark parity as the deciding factor.
Q. What does Manifold-Constrained Hyper-Connections mean for fine-tuning V4 on proprietary data?
MCHC imposes geometric constraints on expert connectivity weight space during pretraining that improve training stability and inference consistency. When fine-tuning V4 on proprietary data, standard LoRA applied naively to expert weight matrices may introduce perturbations that violate the manifold geometry MCHC established, potentially degrading the inference consistency properties that MCHC provides. DeepSeek’s published fine-tuning guidelines recommend MCHC-aware LoRA configurations that constrain updates to perturbations compatible with the manifold structure. Full fine-tuning with manifold constraints maintained is more computationally expensive but produces fine-tuned models that retain V4’s base inference consistency properties more reliably than unconstrained LoRA approaches.
Q. How does DeepSeek V4’s Mixture-of-Experts design compare to Mixtral 8×22B in terms of inference efficiency?
Mixtral 8×22B activates approximately 39 billion of 141 billion total parameters per token (~28% activation ratio) with a relatively simple top-2 routing mechanism. V4 Pro activates approximately 49 billion of 1.6 trillion total parameters per token (~3.1%), sustained by significantly more sophisticated routing, adaptive temperature gating, shared experts, fine-grained segmentation, and MCHC expert connectivity constraints. The absolute activated parameter counts are within striking range of each other, but V4 Pro achieves that activation level while maintaining the quality of a 1.6T parameter model — over 11× more total capacity than Mixtral. The comparison is not that V4 activates fewer parameters in absolute terms, it is that V4 achieves far higher model quality per activated parameter.
Conclusion: the architectural evidence for your infrastructure decision
The practitioner gap in current DeepSeek V4 coverage is not a data deficit, the technical report publishes more architectural detail than any competing frontier model. The gap is analytical: almost no published analysis connects CSA/HCA interleaving ratios to serving latency profiles, the FP4 Lightning Indexer’s top-k selection to multi-agent KV cache dynamics, or MCHC manifold constraints to fine-tuning stability. These connections determine whether an architecture-level model selection decision produces a production infrastructure that performs as expected or requires expensive re-engineering six months after deployment.
For high-volume, long-context, or multi-agent workloads where token volumes justify owned infrastructure, V4 Pro’s architectural design differs from closed-source alternatives in ways that benchmark scores do not capture, specifically in long-context memory management efficiency, inference consistency under sustained agentic deployment, and the operational auditability that architectural transparency enables. V4 Flash is the right choice for organizations with tighter infrastructure budgets, latency-sensitive endpoints, or workloads that do not require the full 1M-token context capability. The right answer is determined by the interaction between your workload profile and your infrastructure capacity, not by a benchmark leaderboard position.
If you are currently in an infrastructure evaluation comparing DeepSeek V4 Pro or Flash against Claude Opus or an OpenAI offering, download the DeepSeek V4 technical report and map the CSA/HCA compression ratios and Lightning Indexer top-k budget against your projected KV cache footprint at your target context length and batch size before finalizing the comparison. That single calculation will tell you more about the right architecture for your workload than any leaderboard score.
Sources
https://amitray.com/wp-content/uploads/2025/12/DeepSeek-Sparse-Attention-DSA-Mechanism-scaled.jpg
https://behope.com/cdn/shop/files/4x.png?v=1769012471&width=1920
{kind=link}
{kind=link}
💡 Want to share your work on my socials with my 15k+ audience?
If you build a project you are excited about, I will be too.
Trust me! I love seeing people build cool stuff. To share it, you can contact me here.
Did you enjoy this post?
Here are some other AI Agents posts you might have missed:
You’re receiving this because you’re part of our mailing list. We don’t spam or sell your information. To unsubscribe, use the link below.
Ready to take it to the next level? Check out my AI Agents for Enterprise course on Maven and be part of something bigger, join hundreds of builders developing enterprise-level agents.
Join the next cohort of my Agent Engineering Bootcamp (Developers Edition) May 30th (15% discount)
You’re receiving this because you’re part of our mailing list. We don’t spam or sell your information. To unsubscribe, use the link below.