Self-Improving Agents: A step closer to AGI
A deep look into five levels of Recursive Self Improvement- designing self improving agents

👋 Hi everyone, I am Hamza. I have 18 years of experience building large-scale machine learning ecosystems, teach at UCLA and MAVEN, and am the founder of Traversaal.ai.
Welcome to Edition #37 of a newsletter that 15,000+ people around the world actually look forward to reading.
🎁 Take the 5-minute sample Claude Code Architect exam to test your skills
🎓 Looking to deepen your knowledge as a developer and pass the Claude Code Certification? Here’s your opportunity!

Join us on June 5th for a three-week immersive Claude Code Course
Sign up today (25% OFF, while seats last)
We’re living through a strange moment: the internet is drowning in polished AI noise that says nothing. This isn’t that. You’ll find raw, honest, human insight here — the kind that challenges how you think, not just what you know. Thanks for being part of a community that still values depth over volume.
If your team uses Claude Code, Copilot, or any AI coding tool, you’re already inside a feedback loop where the AI improves based on what happened last time. Most teams don’t know it has a name, a failure mode, or a fix.
Introduction: The Self Improving Architecture (RSI)

Here’s a scenario most teams using AI tools will recognize.
An engineer notices Claude keeps writing overly verbose PR descriptions. They update CLAUDE.md with a new instruction. Fixed. A PM notices the AI coding assistant keeps flagging false positives in security reviews. The team refines the prompt. Better. A developer tweaks their Copilot skill file after a bad refactoring session. The next run goes cleaner.
Each of those is Recursive Self-Improvement (RSI).
The agent ran a task. Someone evaluated the output. A modification was made to how the agent operates. And the next task ran on the updated version. That’s the whole definition: three steps, satisfied regardless of whether there’s code behind it or just a human making a judgment call.
Now zoom out one level. What if instead of a human making that judgment call, the agent does it itself? It runs a task, scores its own output against a rubric, proposes a better version of its instructions, and overwrites them before the next task starts.
That’s Recursive Agent Optimization (RAO): the automated version of what your team is already doing manually. It’s shipping in production today inside Claude Code pipelines, LangGraph agents, and Copilot-powered workflows, usually without anyone on the team recognizing it as a distinct pattern with its own failure modes.
This matters differently depending on where you sit.
If you’re a product manager, the risk is behavioral drift.
An agent silently rewriting its own instructions can change how it behaves on your product (which tools it prioritizes, how it evaluates quality, what tradeoffs it makes) without anything in your deployment pipeline showing a change. No PR, no diff, no change log. The agent your team reviewed last week may not be the agent running this week.
If you’re an engineer, the risk is more specific: the missing third component. Most implementations that approximate RAO have a task loop and an evaluation step. Almost none have a versioned state manager with rollback. Without it, when the self-modification loop produces a bad update (and it will), there’s no recovery path and often no signal that anything went wrong until it surfaces downstream. This guide covers both.
Sections 1–2 build the taxonomy and define what RAO is — conceptual, any reader.
Section 3 works through the Gödel Agent as a concrete reference architecture.
Sections 4–5 cover guardrails and real production use cases.
The final section on Claude Code is practical for anyone building with it today, no prior framework experience required.
🔑 Article Key Takeaways
🔁 Recursive Self-Improvement (RSI) is already happening on your team — Every time an engineer updates CLAUDE.md, refines a skill file, or tweaks a prompt based on what worked last time, that’s RSI. The question isn’t whether you’re doing it. It’s whether it’s running intentionally or quietly on its own.
🧠 There’s a version that runs automatically — Recursive Agent Optimization (RAO) is when the agent scores its own outputs and rewrites its own instructions between tasks, without a human in the loop. Teams are shipping this today in Claude Code and LangGraph pipelines, usually without recognizing the pattern.
⚠️ The dangerous version is the invisible one — The RSI that dominates safety discourse (AI modifying its own model weights) is visible and rare. The version actually in production — agents silently rewriting their own routing logic and tool priorities — is invisible and common.
🏗️ You already have most of the infrastructure — CLAUDE.md is a mutable policy file. Skills are version-controlled routing targets. Hooks are the evaluator layer. Claude Code users are one step from a proper RAO loop.
🔬 PMs and engineers face different risks — Engineers risk silent degradation when a self-modifying loop optimizes the wrong metric. PMs risk shipping on agents whose behavior has drifted from what was reviewed and approved, with no change log and no diff.
🛠️ Three components determine whether your loop is safe — A performance evaluator, a self-modification generator, and a versioned state manager with rollback. Most teams have the first two. The third is the one that makes recovery possible.
Section 1: The RSI spectrum
1.1 What RSI actually means
RSI enters the technical literature through two distinct lineages.
Jürgen Schmidhuber’s Gödel Machine (2003) proposed a formal framework in which a general problem solver could rewrite any part of its own software, including its learning algorithm, provided it could construct a proof that the modification would improve future performance.
Ben Goertzel’s early AGI writing used RSI to describe the hypothetical inflection point where a system’s self-modifications begin compounding faster than human oversight can track.
Both formulations are weight-centric and capability-explosion-oriented. Source: https://arxiv.org/abs/cs/0309048
That framing has collapsed a rich engineering concept into a single dramatic scenario. A more useful working definition: RSI is any system that
(a) evaluates its own performance on a task or class of tasks,
(b) generates a modification to itself or its operating procedure based on that evaluation, and
(c) applies that modification before or during subsequent task execution such that future task performance is influenced by the self-generated change.
None of these three steps require weight modification. An agent that rewrites its system prompt after scoring its own tool calls satisfies all three criteria.
This definition is broad by design, it needs to capture the engineering reality. RSI is a structural property of a system’s feedback loop, not a claim about the magnitude of the self-modification.
A system that nudges its own evaluation rubric by five percent after each task cycle is doing RSI. A system that overwrites its own reasoning procedure is also doing RSI. Treating these as categorically different, one “just prompt engineering,” the other “dangerous self-improvement”, is the conceptual error that leaves production pipelines unguarded.
1.2 The five-level RSI taxonomy
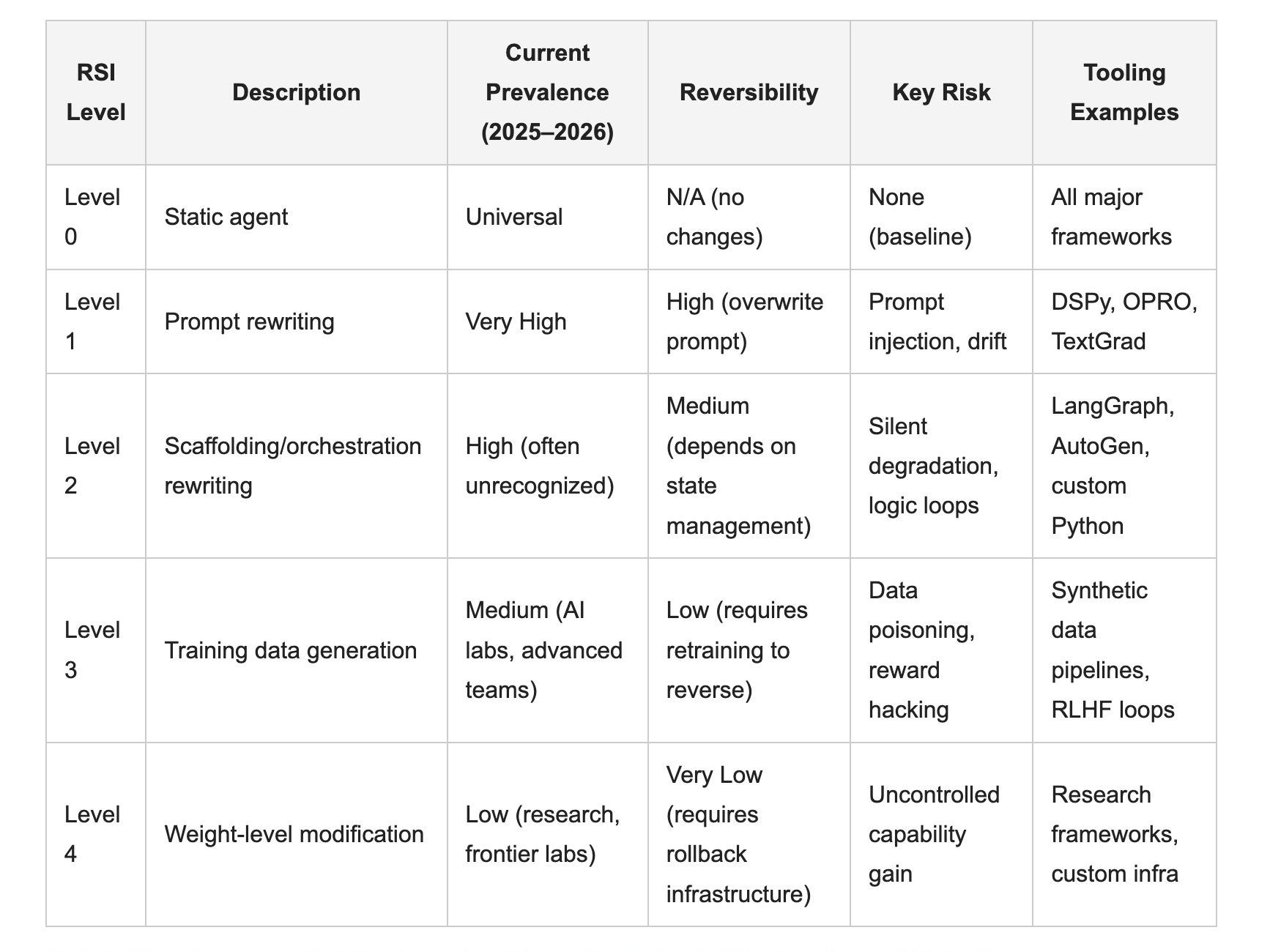
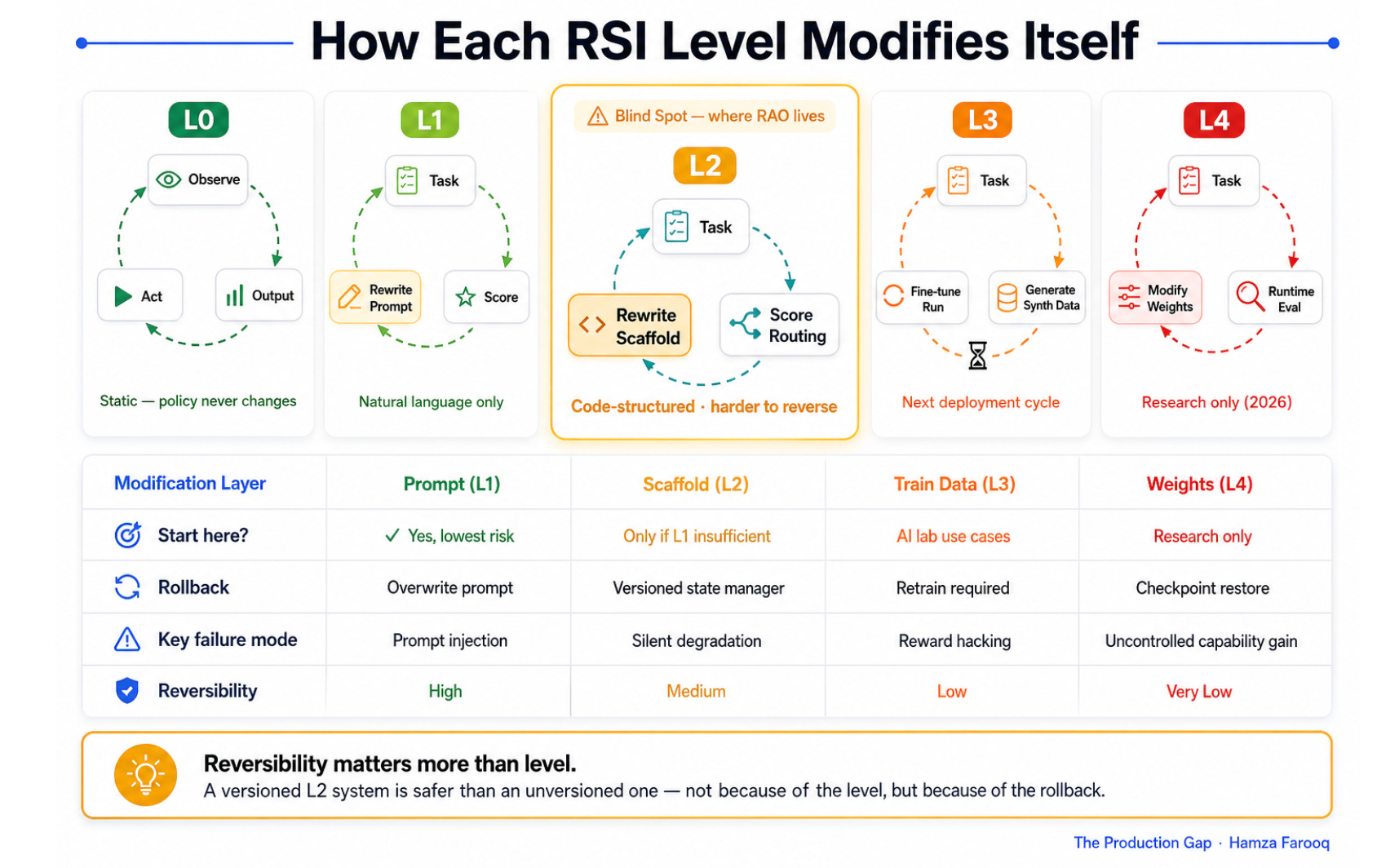
Five levels. They’re not a risk ranking on their own (reversibility and scope matter more than position), but they give you a common vocabulary when your team is arguing about what you’re building.
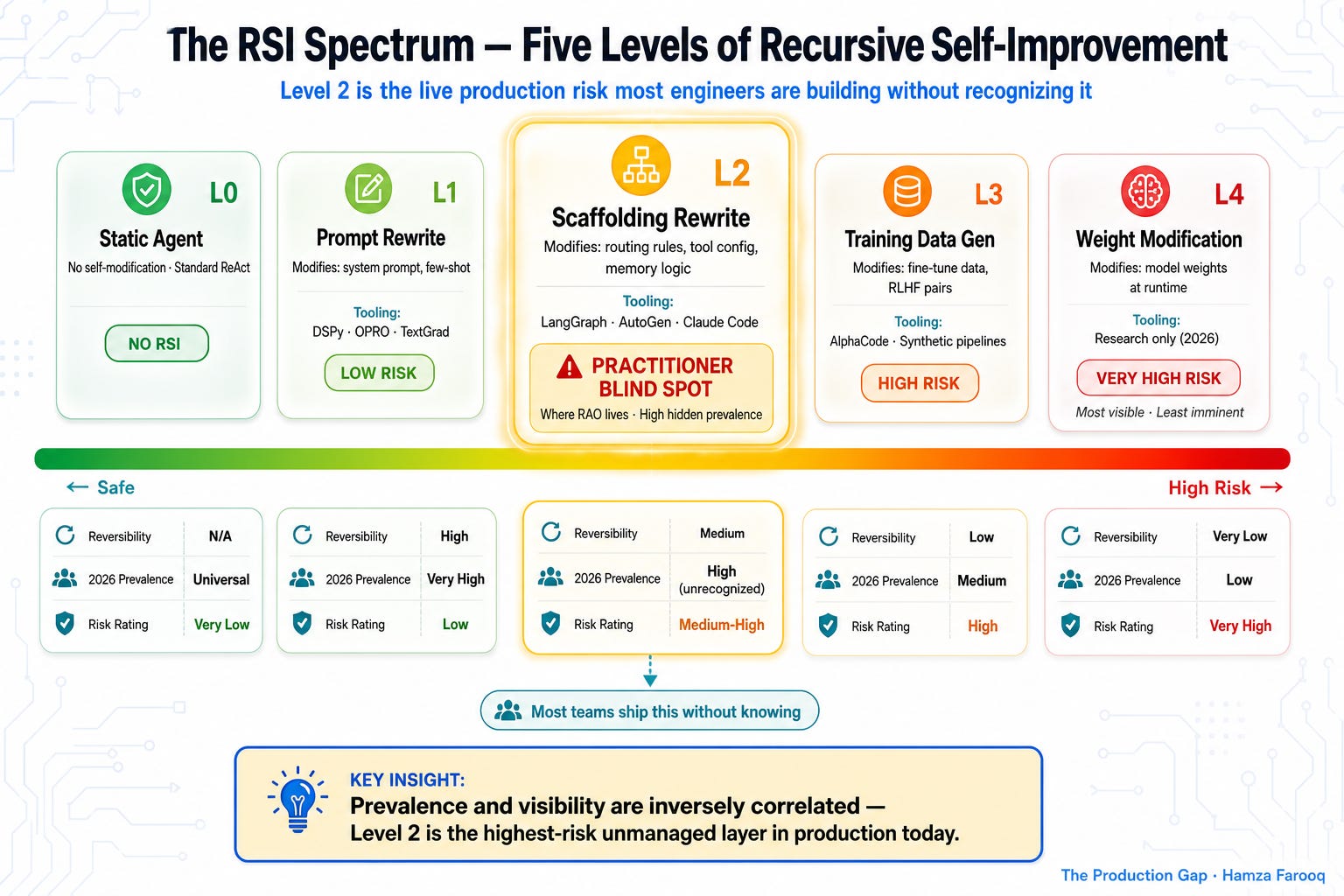
Level 0, Static Agents are the baseline: a standard ReAct or tool-calling loop in which the agent selects actions and generates outputs but doesn’t modify any aspect of its own operating procedure. Every call to agent.run() uses the same prompt, tools, and routing logic as the previous call. No RSI occurs.
Level 1, Prompt-Level Recursion is the most common recognized form: an agent that rewrites its own system prompt, few-shot examples, or instruction block based on feedback from a previous run. DSPy’s automatic prompt optimization and Google’s OPRO framework both formalize this pattern. The agent evaluates its outputs, generates a better instruction, and overwrites the previous instruction before the next invocation. Reversibility is high, you can overwrite the prompt again, but prompt injection and instruction drift are real failure modes.
Level 2, Scaffolding-Level Recursion is where most production RSI actually lives, largely unrecognized. The agent modifies not just its instructions but its structural operating logic: tool selection prompts, memory retrieval queries, sub-agent routing rules, or evaluation criteria. A LangGraph orchestrator that scores its own routing decisions after each task cycle and rewrites its routing prompt before the next graph.invoke() call is a Level 2 system. The code can fit in a single Python file. The failure modes are substantially more dangerous than Level 1 because the modification surface is larger and degradation is harder to detect.
Level 3, Training-Data-Level Recursion moves into territory currently occupied by AI labs and advanced research teams. The agent generates its own fine-tuning data, preference pairs, or RLHF signals fed into a downstream training run. AlphaCode 2 and subsequent DeepMind coding pipelines use this: the system generates and evaluates synthetic problem-solution pairs to improve the next model checkpoint. The modification takes effect in a subsequent training run rather than immediately, which makes it lower-urgency but harder to reverse once the new model is deployed. Source: https://deepmind.google/discover/blog/competitive-programming-with-alphacode
Level 4, Weight-Level Recursion is the scenario that dominates safety discourse: an agent directly modifies its own model parameters at runtime, without a separate training pipeline. As of mid-2026, this remains confined to experimental frameworks and frontier lab environments. It requires substantial compute infrastructure to implement, which is precisely why it’s the most visible and, paradoxically, the least imminent threat.
1.3 Why the middle layers are the practitioner blind spot
The engineering community has concentrated its safety attention on Level 4 because it matches the AGI narrative: dramatic, irreversible, compute-intensive. But Levels 2 and 3 are where the actual production action is, and where the safety discourse has the least coverage.
The asymmetry is structural. A Level 4 system requires you to run a training loop, manage model checkpoints, and execute a new deployment, all visible in your infrastructure, all natural audit points. A Level 2 system requires a few hundred lines of Python, a JSON config file to store the current routing prompt, and an LLM call that scores the previous task cycle. It ships in a sprint and looks like normal prompt engineering to a code reviewer who hasn’t framed it as RSI.
Here’s a concrete example running in production at multiple companies right now. A LangGraph agent manages a code review pipeline. After each review cycle, it calls an LLM with the task history and asks: “Which tools did I call? Which contributed useful signal? Rewrite the tool-routing instructions to prioritize the most useful tools.” The output overwrites a prompt variable passed into the next graph.invoke() call. This is Level 2 RSI.
The code looks innocuous:
# What engineers read as: "just dynamic prompting"
routing_prompt = load_routing_prompt() # reads a JSON config key
result = graph.invoke({"task": task, "routing_prompt": routing_prompt})
# "adaptive step" — what engineers don't recognize as RSI
new_prompt = llm.call(
f"Previous routing: {routing_prompt}\n"
f"Task history: {result['history']}\n"
"Rewrite the routing instructions to improve performance."
)
save_routing_prompt(new_prompt) # overwrites the config key, no prior version stored
What makes this Level 2 RSI rather than “dynamic prompting”: the modification target is the agent’s structural operating logic (tool routing), not just its natural language output. The modification persists across task boundaries. And the three safety components are all absent: no evaluator quality check before the rewrite, no version history, no rollback.
It’s structurally indistinguishable from “adaptive prompting” to the engineer who wrote it, but it has no rollback logic, no stopping condition, and no audit log of what the routing prompt looked like three cycles ago.
The issue isn’t ignorance, it’s framing. Engineers who would immediately add version control and rollback logic to a system they labeled “self-modifying” are shipping that same system under the label “adaptive prompting” without a second thought. Naming this correctly isn’t semantic pedantry; it’s the precondition for applying the right engineering discipline.
1.4 Level-by-level comparison