
Semantic Caching for RAG Systems
When to Use It, What to Cache, How to Evaluate It?


👋 Hi everyone, Hamza.
Welcome to Edition #28 of a newsletter that 15,000+ people around the world actually look forward to reading.
We’re living through a strange moment: the internet is drowning in polished AI noise that says nothing.
This isn’t that. You’ll find raw, honest, human insight here, the kind that challenges how you think, not just what you know. Thanks for being part of a community that still values depth over volume.
🎓 Want to up skill in AI?
Join the next cohort of my Agent Engineering Bootcamp (Developers Edition) April 8
Watch the free 4-session Agent Bootcamp playlist on YouTube
Preamble
Running an LLM for every user query is the fastest way to burn budget and add latency.
In real-world RAG workloads, users often ask the same thing in slightly different words, yet a naive pipeline still reruns retrieval and regeneration each time.
Semantic caching fixes this “always compute” inefficiency by matching queries in embedding space and reusing prior results when the meaning is similar, not the exact text.
Understanding Semantic Caching for RAG Systems
Semantic caching stores and reuses query results based on meaning rather than exact text matches. This approach solves performance problems in LLM applications without sacrificing quality.
Modern semantic cache systems change how you optimize RAG architecture. Traditional caches need identical queries to work. Semantic caches recognize similar questions and serve stored responses. This cuts redundant LLM calls and speeds up your system by up to 300%.
Building a working RAG system is one thing. Scaling it efficiently is another. As query volumes grow and users expect faster responses, you need better caching strategies. Research shows poorly optimized systems waste 60-80% of processing time on redundant operations that semantic caching eliminates.
This guide covers the technical architecture, implementation strategies, and evaluation methods for semantic cache systems. You’ll get the practical knowledge needed to transform your RAG performance.
RAG Architecture and Semantic Caching Basics
Core RAG Components
RAG architecture has three main parts: the retrieval system, the augmentation layer, and the generation component. Each part offers opportunities where semantic caching reduces delays.
The retrieval system forms the foundation. Vector databases like Pinecone, Weaviate, or Chroma search through large document collections. This component takes up 40-60% of total system delay. When users submit queries, the system converts them into vector embeddings, searches the knowledge base, and returns relevant document chunks.
The augmentation layer processes retrieved documents. You rank and filter results based on relevance scores and metadata. This stage involves extra LLM calls for reranking and context preparation, adding another 20-30% to total delay. The generation component combines retrieved context with the original query to produce the final response.
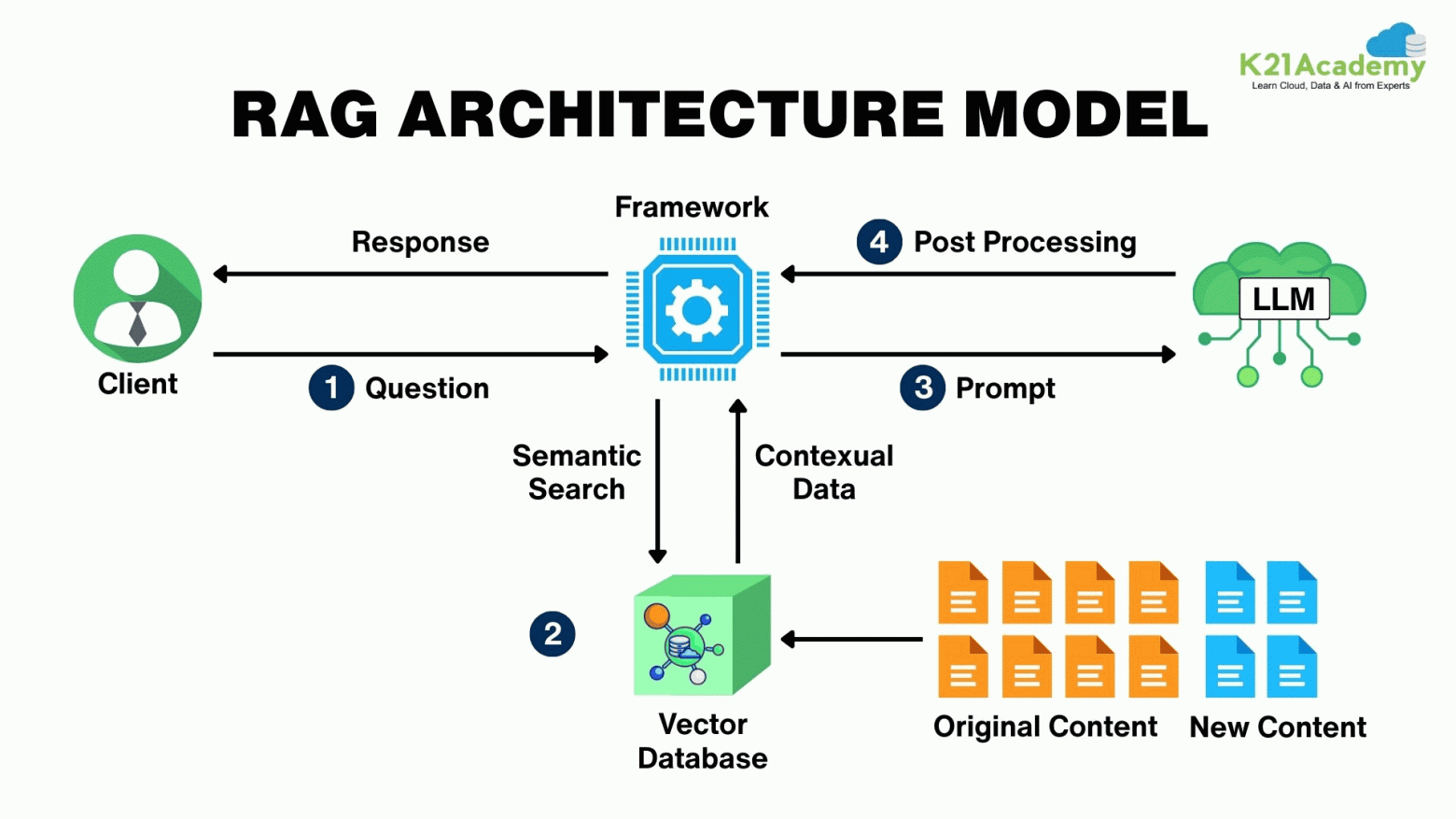
Source : https://habr.com/ru/articles/977260/
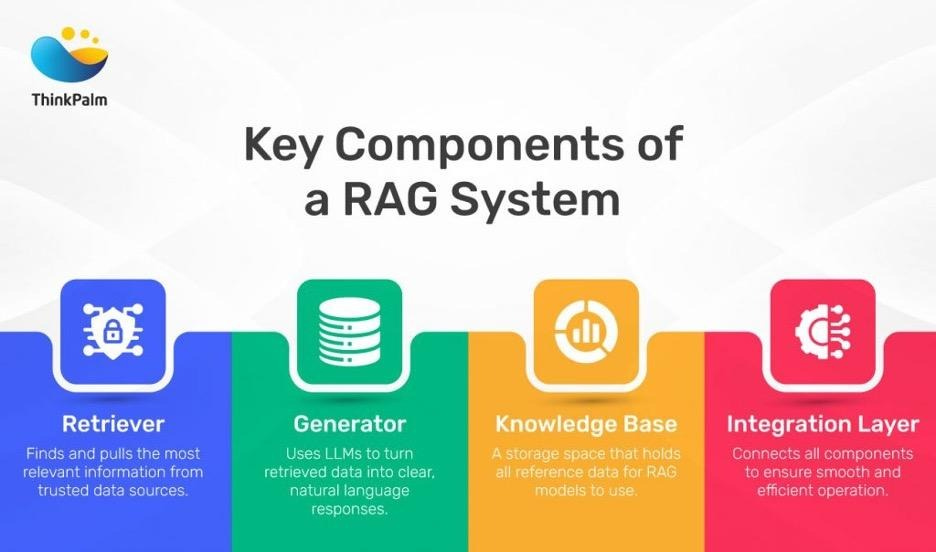
Source: ThinkPalm — https://thinkpalm.com/blogs/what-is-retrieval-augmented-generation-rag/
How Semantic Caching Works with LLMs
Semantic caching recognizes that many user queries share meaning even when worded differently. Traditional caches miss these opportunities because they need exact string matches. For example, “How to optimize database performance?” and “What are the best practices for speeding up SQL queries?” would generate separate cache misses despite asking for similar information.
Semantic caching uses vector embeddings to calculate cosine similarity between queries. This helps the system identify when cached responses work for new but related questions. The approach transforms caching from a binary hit-or-miss system into a nuanced similarity-based retrieval mechanism.
The technology addresses retrieval augmented generation bottlenecks by creating multiple cache layers:
Query-level caching for similar questions
Context-level caching for retrieved document chunks
Response-level caching for generated outputs
Each layer reduces different types of computational overhead while maintaining response quality.
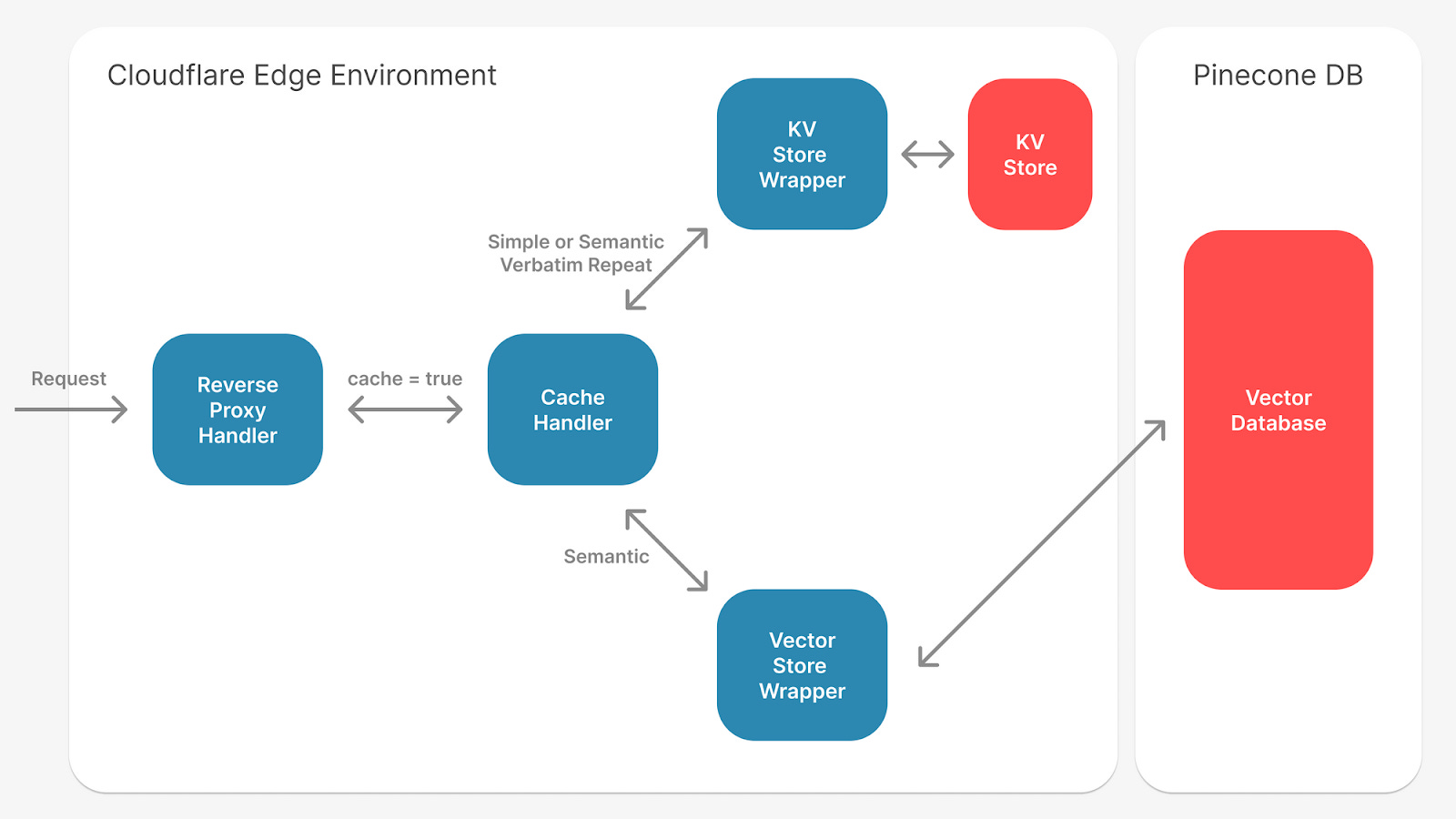
Source: https://portkey.ai/blog/reducing-llm-costs-and-latency-semantic-cache/
Building a Semantic Cache System
Modern semantic cache systems use a multi-layered architecture that integrates with existing RAG components. The primary cache layer sits between the user interface and the retrieval system, intercepting incoming queries and checking for semantically similar cached responses.
The embedding generation component converts new queries into vector representations using the same model employed by the underlying RAG system. This consistency ensures similarity calculations remain accurate. Popular embedding models like OpenAI’s text-embedding-ada-002 or Sentence Transformers provide the vector representations needed for effective semantic matching.
Cache storage systems must support high-dimensional vector operations while maintaining fast lookup times. Redis with vector search capabilities, Elasticsearch with dense vector fields, or specialized vector databases serve as the backbone for semantic cache storage. The cache management layer handles similarity threshold enforcement, cache invalidation policies, and performance monitoring.
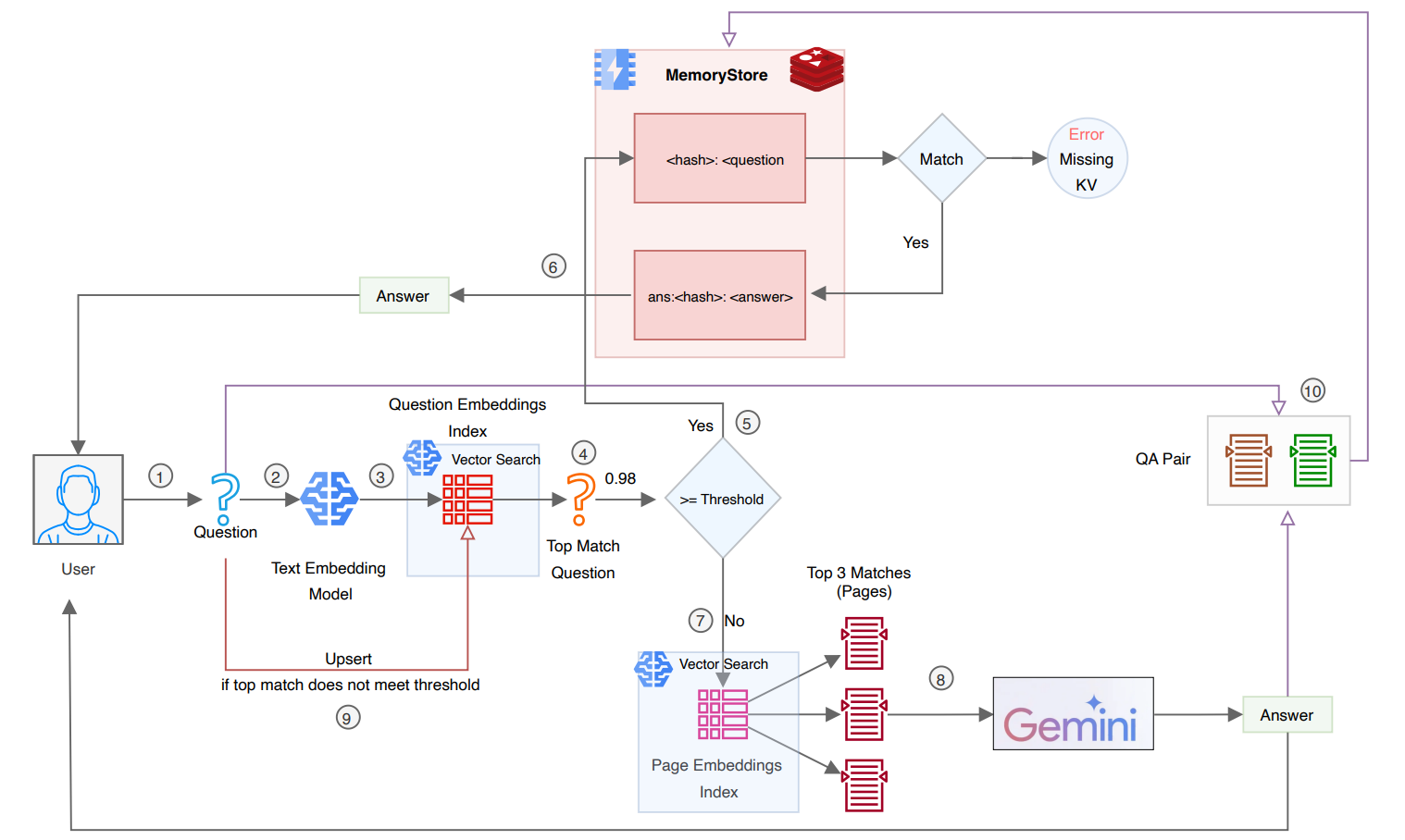
Performance Impact of Semantic Caching
Measured Speed Improvements
Production deployments of semantic cache systems show substantial performance improvements. Organizations report 3-5x speed reductions for repeated or similar queries, with cache hit rates ranging from 30-70% depending on use case patterns and similarity threshold settings.
Real-world data shows:
Customer support chatbots achieve response times of 200-400ms with semantic caching, compared to 1.2-2.5 seconds without
Knowledge management systems drop from 10-15 seconds to 2-4 seconds when cache hits occur
Organizations processing 1 million queries monthly see 40-60% reductions in inference costs
Optimizing Cache Hit Rates
Effective evaluation methods reveal optimal similarity thresholds typically range between 0.85-0.95 cosine similarity, depending on domain specificity and acceptable response variation. Lower thresholds increase cache hit rates but risk serving less relevant responses. Higher thresholds maintain quality at the expense of caching effectiveness.
Dynamic threshold adjustment based on query patterns and user feedback enables systems to optimize for specific use cases:
Customer service applications often benefit from lower thresholds (0.82-0.87) due to repetitive question patterns
Technical documentation systems require higher thresholds (0.92-0.97) to maintain accuracy
Cache performance monitoring reveals effective systems achieve 45-65% hit rates within the first week of deployment. Rates climb to 60-80% as the cache builds comprehensive coverage of common query patterns. The initial warm-up period typically requires 10,000-50,000 queries depending on domain complexity.
Resource Efficiency
Semantic caching dramatically reduces computational overhead across multiple system components:
Vector database query loads decrease by 40-70%
LLM inference costs drop proportionally to cache hit rates, with high-performing systems reducing API calls by 50-80%
Memory utilization increases by 10-20% for embedding storage and similarity calculations, but this overhead pays dividends through reduced processing requirements
CPU usage drops significantly during cache hit scenarios
Network bandwidth consumption decreases as cached responses eliminate external API calls
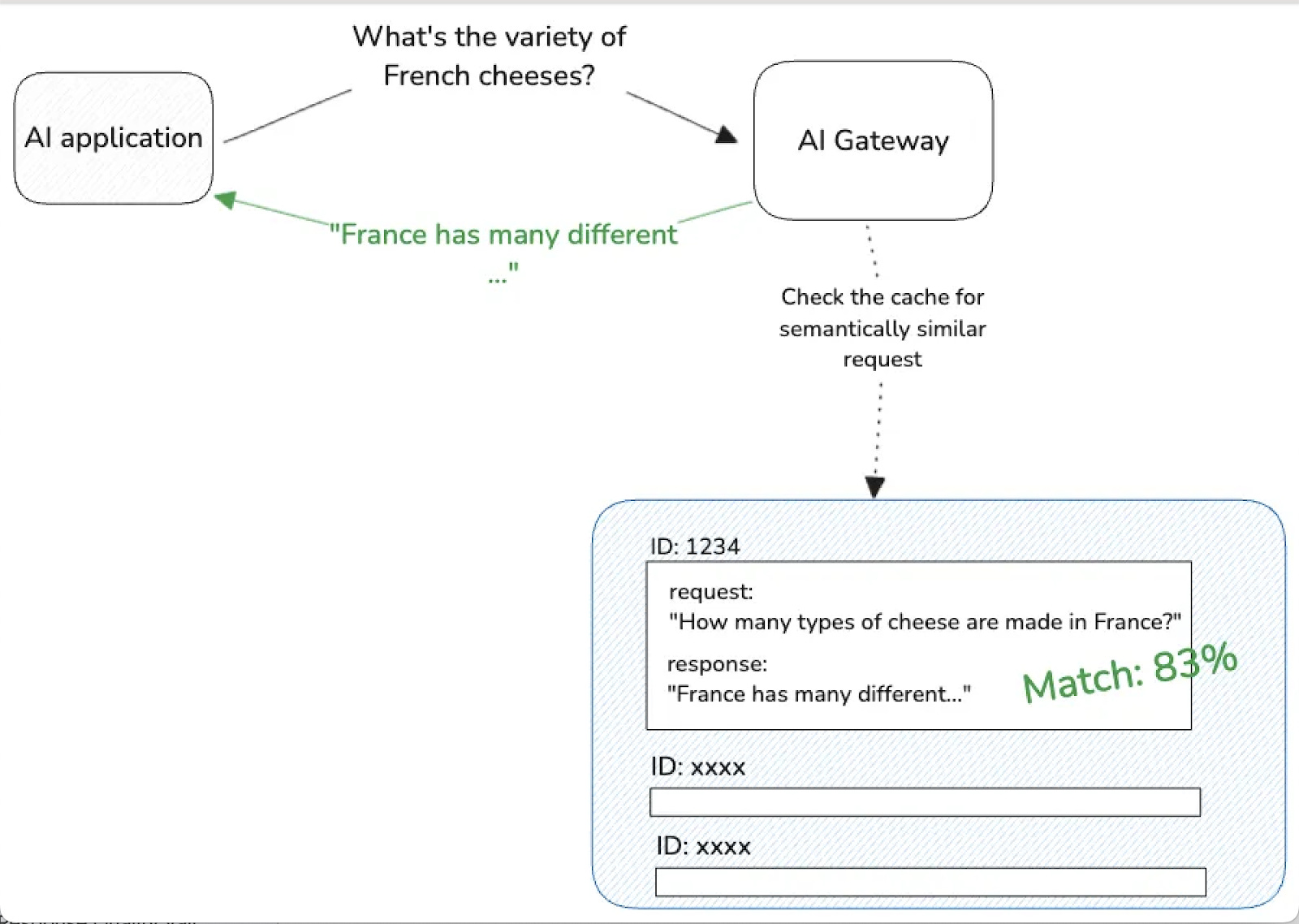
Source: https://www.solo.io/blog/semantic-caching-with-gloo-ai-gateway
Implementation Strategies

 | A guest post by
|